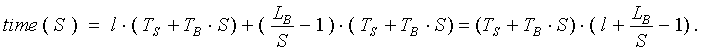Предсказатель
производительности DVM-программ |
- дата последнего обновления 09.01.01 -
Оглавление
1 Введение
2
Принципы реализации Предиктора
2.1 Представление программы в виде иерархии интервалов
2.2 Характеристики выполнения программы на каждом процессоре
2.3 Основные характеристики и их компоненты
2.4 Исходные данные для Предиктора
3.1 Общие принципы моделирования
3.2 Обычные функции
3.3 Функции начала/конца интервала
3.4 Функции ввода/вывода данных
3.5 Функции создания/уничтожения объектов
3.6 Функции распределения ресурсов и данных
3.7 Функции инициализации коллективных операций
3.8 Функции выполнения коллективных операций
3.9 Функции организации параллельного цикла
3.10 Неизвестные функции
4 Оценка накладных расходов доступа к удаленным данным
4.1 Основные понятия и термины
4.2 Оценка обменов при перераспределении массивов
4.3 Оценка обменов границами распределенных массивов
4.4 Оценка обменов при выполнении операций редукции
4.5 Оценка обменов при загрузке буферов удаленными элементами массивов
Приложение
1. Связь имен полей в выходном
HTML-файле и имен полей в структуре
_IntervalResult
Приложение
2. Описание вспомогательных функций
и классов
Приложение
3. Основные функции экстраполятора
времени
Приложение
4. Фрагменты трассы и параметры
моделируемых Предиктором функций
Lib-DVM
Литература
Предиктор предназначен для анализа и отладки производительности DVM-программ без использования реальной параллельной машины (доступ к которой обычно ограничен или сложен). С помощью возможность Предиктора пользователь имеет получить оценки временных характеристик выполнения его программы на MPP или кластере рабочих станций с различной степенью подробности.
Реализация Предиктора представляет собой систему обработки трассировочной информации собранной библиотекой периода выполнения Lib-DVM во время прогона программы на рабочей станции и состоит из двух крупных компонент: интерпретатора трассы (PRESAGE) и экстраполятора времени (RATER). По данным трассировки и параметрам, заданным пользователем, интерпретатор трассы вычисляет и выдает ему экстраполированные временные характеристики выполнения данной программы на MPP или кластере рабочих станций, вызывая функции экстраполятора времени, который в свою очередь моделирует параллельное выполнение DVM-программ, являясь по сути моделью библиотеки Lib-DVM, низлежащей системы передачи сообщений и аппаратуры.
Производительность параллельных программ на многопроцессорных ЭВМ с распределенной памятью определяется следующими основными факторами:
Концептуально работа программы подразделяется на три основных этапа:
2 Принципы реализации Предиктора
2.1 Представление программы в виде иерархии интервалов
Для более детального анализа эффективности программы пользователю предоставлены средства разбиения выполнения программы на интервалы и возможности получения характеристик производительности для каждого из них.
Выполнение программы можно представить в виде последовательности чередующихся интервалов (групп операторов) ее последовательного и параллельного выполнения. По умолчанию, вся программа является одним интервалом. Интервалы задаются пользователем специальными операторами языков C-DVM и Fortran-DVM, либо режимом компиляции, при котором интервалами являются
(Ограничение: при использовании Предиктора не допускается задание целочисленного выражения с интервалом внутри параллельного цикла).
Пользователь может разбить любой интервал на несколько подинтервалов или объединить несколько соседних (по порядку выполнения) интервалов в новый единый интервал (т.е. представить программу в виде иерархии интервалов нескольких уровней; самый высокий уровень всегда имеет вся программа целиком - уровень 0).
Механизм разбиения программы на интервалы служит для более детального анализа поведения программы во время ее выполнения. При просмотре результатов с помощью Предиктора, пользователь имеет возможность задать глубину детализации, то есть исключить из рассмотрения интервалы, начиная с некоторого уровня вложенности.
Для упрощения дальнейшего описания введем следующие понятия. Интервал будем называть простым, если он не содержит внутри себя других интервалов (вложенных интервалов). Интервалы, включающие в себя вложенные интервалы, будем называть составными. Таким образом, программа в целом представляет собой дерево интервалов: интервал самого высокого уровня, представляющий всю программу, является его корнем; тот из них, который имеет самый низкий уровень, является интервалом листом.
Во время обработки трассировочной информации один из интервалов являются активным интервалом (т.е. интервалом, в котором находится исполняемый в данный момент оператор программы и являющийся самым “нижним” в дереве интервалов). Для него в это время собирается следующая информация:
На этом же этапе подсчитывается количество коммуникационных операций, выданных программой внутри данного интервала:
В Предикторе каждому интервалу соответствует объект типа “Interval”, который содержит в себе необходимые характеристики интервала; в процессе интерпретации трассы строится дерево интервалов. Каждый интервал включает в себя вектор подобъектов “Processor”, элемент которого хранит характеристики процессора, участвующего в выполнении интервала (заметим, что в условиях задачного параллелизма не все процессоры могут принимать участие в выполнении какого-либо интервала). Таким образом, после завершения этапа интерпретации трассы имеется дерево интервалов с узлами “Interval” с накопленными характеристиками (IntervalType, EXE_count, source_file, source_line, num_op_io, num_op_reduct, num_op_shadow, num_op_remote, num_op_redist). В то же самое время осуществляется сбор характеристик для каждого процессора, исполняющего интервал, в соответствующем ему объекте “Processor”.
2.2 Характеристики выполнения программы на каждом процессоре
Объект “Processor” хранит следующие характеристики процессора, участвующего в выполнении интервала:
Как уже отмечалось выше, сбор этих характеристик осуществляется на первом этапе моделирования – этапе интерпретации трассы; они сохраняются в объекте “Processor”, существующем для каждого интервала и каждого процессора, исполняющего данный интервал.
В процессе интерпретации трассы строится “дерево интервалов” (дерево объектов “Interval”), каждый из которых содержит вектор объектов “Processor”. Размер вектора равен числу процессоров в корневой процессорной топологии, но “значащими” элементами являются те, которые соответствуют процессорам, на которых выполняется интервал.
2.3 Основные характеристики и их компоненты
Возможность интерпретировать трассу, накопленную Lib-DVM на этапе модельного выполнения программы, позволяет Предиктору выдать пользователю следующие основные показатели выполнения параллельной программы как для всей программы в целом, так и для каждого ее интервала:
- Полезное время (Productive_time), это время, которое потребуется для выполнения параллельной программы на однопроцессорной ЭВМ (это время можно разложить на три компонента:
- полезное пользовательское время (Productive_CPU_time) – время, которое программа потратила на нужные “пользовательские” вычисления.
- полезное системное время (Productive_SYS_time) - время, которое программа потратила на нужные “системные” вычисления (обращения к Lib-DVM).
- время ввода-вывода (IO_time) - время, которое программа потратила на ввод/вывод.
- Общее время (Total_time) использования процессоров, которое вычисляется как произведение времени выполнения на общее число используемых процессоров.
Коэффициент эффективности равен отношению полезного времени к общему времени использования процессоров.
- Недостаточный параллелизм (Insuff_parallelism) - потери из-за недостатка параллелизма, приводящего к дублированию вычислений на нескольких процессорах.
- Коммуникации (Communication) - потери из-за выполнения межпроцессорных обменов.
- Простои (Idle) - потери из-за простоев тех процессоров, на которых выполнение программы завершилось раньше, чем на остальных.
Более подробно сущность вышеперечисленных характеристик описана в работе [1].
После того, как дерево объектов “Interval” построено, для каждого объекта вызывается метод “Integrate”, который осуществляет расчет характеристик интервала по соответствующим характеристикам вектора процессоров и по характеристикам вложенных интервалов. В заключение по дереву интервалов создается HTML-файл путем вписывания вычисленных значений в специальный “шаблон”, соответствующий одному интервалу (смотри файл IntervalTemplate.cpp). Соответствие полей объекта “Interval” и видимых полей HTML-файла приведено в Приложении 1.
2.4 Исходные данные для Предиктора
Исходными данными для моделирования служат трассировка выполнения данной программы на одном процессоре, конфигурационная информация, записанная в каком либо файле (например, “Predictor.par”) и параметры командной строки. Для получения трассы нужного содержания в конфигурационный файл usr.par необходимо внести следующие параметры:
| Is_DVM_TRACE=1; | - трассировка включена; |
| FileTrace=1; | - накапливать трассировку в файлах; |
| MaxIntervalLevel=3; | - максимальный уровень вложенности интервалов; |
| PreUnderLine=0; | - не подчеркивать call в файле трассы; |
| PostUnderLine=0; | - не подчеркивать ret в файле трассы; |
| MaxTraceLevel=0; | - максимальная глубина трассы для вложенных функций |
Параметры PreUnderLine, PostUnderLine и MaxTraceLevel являются указанием Lib-DVM на то, что не надо накапливать в трассе строки, состоящие из подчеркиваний, а также не надо трассировать вложенные вызовы функций Lib-DVM, что приводит к существенному сокращению размера файла трассы.
Замечание. При запуске на одном процессоре параллельной программы, в которой явно указана требуемая ей конфигурация процессоров или предусмотрена динамическая настройка на выделенное количество процессоров, необходимо задать соответствующую “виртуальную” процессорную систему с помощью параметров IsUserPS и UserPS.
Например, для задания “виртуальной” процессорной системы 2*2 значения параметров будут следующими:
| IsUserPS=1; | - использовать задание “виртуальной” процессорной системы; |
| UserPS=2,2; | - топология “виртуальной” процессорной системы. |
Рассмотрим фрагмент трассировки:
1. call_getlen_ TIME=0.000005 LINE=31
FILE=GAUSS_C.CDV
2. ArrayHandlePtr=951cd0;
…
3. ret_getlen_ TIME=0.000002 LINE=31 FILE=GAUSS_C.CDV
4. Res=4;
Строка 1 является строкой, идентифицирующей вызываемую функцию Lib-DVM (getlen_). Она содержит:
Строка 2 (и возможно последующие строки) содержат имена и значения фактических параметров вызываемой функции. Они преобразуются в соответствующие исходные числовые значения, пакуются в структуры и используются при интерпретации каждой функции Lib-DVM.
Строка 3 трассирует возврат из функции Lib-DVM. Единственное значение, которое используется Предиктором – это время (назовем его ret_time) выполнения функции (TIME=0.000002); обычно оно суммируется в поле SYS_Time структуры “Interval”.
Строка 4 содержит возвращаемое функцией значение и используется аналогично строке 2.
Заметим, что каждая функция Lib-DVM обрабатывается Предиктором по своему алгоритму, хотя многие из них (так называемые “неизвестные” и “обычные” функции) обрабатываются по одному и тому же “основному” алгоритму.
Конфигурационная информация Предиктора задается в специальном файле (назовем его для определенности “Predictor.par”). Этот файл определяет характеристики моделируемой многопроцессорной системы и имеет следующую структуру:
// System type = network | transputer
type = network;
// Communication characteristics (mks)
start time = 75;
send byte time = 0.2;
// Comparative processors performance
power = 1.00;
// Topology - optional
topology = {2, 2};
Предложения, начинающиеся с “//” являются комментариями. Параметр Topology (является необязательным) определяет топологию виртуальной процессорной системы, т.е. ее ранг и протяженность по каждому из измерений. Значение параметра type равное network говорит о том, что процессорная система является сетью рабочих станций, а значение transputer указывает на то, что целевая процессорная система в качестве коммуникационной сети использует систему транспьютерного типа. Для вычисления времени передачи n байт используется линейная апроксимация
T = (start time) + n *( send byte time),
где:
start time –
стартовое время установок передачи
данных, а
send byte time -
время передачи одного байта.
Параметр power задает отношение производительности процессора, на котором работает предсказатель, к производительности процессора, на котором будет реально запущена параллельная программа.
Порядок следования параметров в файле несущественен.
Структура выходного HTML-файла совпадает со структурой интервалов в программе. Каждому интервалу соответствует свой параграф, в котором записаны данные, характеризующие данный интервал и интегральные характеристики выполнения программы на данном интервале и ссылки на параграфы с информацией о вложенных интервалах. Для навигации по файлу в конце каждого параграфа имеются соответствующие кнопки.
3.1 Общие принципы моделирования
Первым этапом моделирования является построение call-графа вызовов функций Lib-DVM c фактическими параметрами. Такой граф является линейной последовательностью call-ов, т.к. вложенные вызовы не обрабатываются (и даже не накапливаются в трассе, собранной для работы Предиктора. Построение call-графа выполняется за три шага
Файл трассы ->
вектор объектов TraceLine ->
вектор объектов FuncCall
На втором этапе работы программы осуществляется собственно моделирование выполнения программы на заданной многопроцессорной системе.
Для вычисления характеристик выполнения программы производится моделирование вызовов функций Lib-DVM в той же последовательности, в которой они находились в трассировке. В ходе моделирования используются следующие вспомогательные структуры и массивы структур:
Элементы массивов создаются и уничтожаются по мере последовательного моделирования вызовов в соответствии с тем, как это происходило при выполнении программы.
Все функции системы поддержки с точки зрения их моделирования можно условно разделить на следующие классы:
В последующих разделах будут детально рассмотрены принципы моделирования функций, входящих в данные классы.
В данную группу входят функции, выполняющиеся на каждом из процессоров моделируемой параллельной системы (или той ее подсистемы, на которую отображена текущая задача), причем время их выполнения не зависит от конфигурационных параметров и совпадает со временем выполнения на однопроцессорной машине (учетом отношения производительности процессоров). Если для функции Lib-DVM не указано явно, то такая функция априори моделируется по данному алгоритму.
Моделирование: времена call_time и ret_time прибавляются к Execution_time, время call_time к CPU_time, а ret_time к SYS_time каждого из процессоров. Кроме того, к Insuff_parallelism_USR каждого процессора прибавляется время, рассчитанное по формуле:
T = Tcall_time * (Nproc - 1) / Nproc
а к Insuff_parallelism_SYS прибавляется время
T = Tret_time * (Nproc - 1)/ Nproc
Данный алгоритм моделирования времени является основным. Далее будем предполагать, что время выполнения моделируются по этому алгоритму, за исключением тех случаев, когда при описании моделирования функции явно указан отличный от этого алгоритм.
3.3 Функции начала/конца интервала
В данную группу входят функции, служащие ограничителями интервалов, из которых состоит моделируемая программа.
Функции:
| binter_ | Создание пользовательского интервала |
| bploop_ | Создание параллельного интервала |
| bsloop_ | Создание последовательного интервала |
Алгоритм моделирования: в массиве интервалов, вложенных в текущий интервал, ищется интервал с таким же именем файла с исходным текстом, таким же номером строки и значением выражения (если требуется) и таким же типом, как и в трассе (source_file, source_line). Тип интервала определяется исходя из того, какая именно функция начала интервала встретилась в трассировке, в соответствии со следующей таблицей:
| binter_ | Пользовательский (USER) |
| bsloop_ | Последовательный (SEQ) |
| bploop_ | Параллельный (PAR) |
Если такой интервал найден, то значение EXE_count для данного интервала увеличивается на 1, в противном случае создается новый элемент в массиве вложенных в текущий интервал интервалов с равным 1 значением EXE_count. После этого найденный или созданный интервал становится текущим.
Функции:
| einter_ | - закрытие пользовательского интервала; |
| eloop_ | - закрытие последовательного и параллельного интервалов. |
Алгоритм моделирования: текущим становится внешний по отношению к текущему интервал. Осуществляется коррекция времен в соответствии с основным алгоритмом.
3.4 Функции ввода/вывода данных
В данную группу входят функции, предназначенные для ввода/вывода данных. Такие функции выполняются на процессоре ввода-вывода.
Алгоритм моделирования: алгоритм моделирования времени отличается от основного. Время выполнения функции прибавляется к Execution_time и к IO_time только процессора ввода-вывода. Некоторые из этих функций рассылают результат выполнения по всем процессорам. В таком случае время рассылки прибавляется к IO_comm всех процессоров.
3.5 Функции создания/уничтожения объектов
В данную группу входят функции, создающие и уничтожающие различные объекты библиотеки поддержки Lib-DVM. Когда одна из таких функций встречается в трассировке, необходимо либо создать и инициализировать, либо удалить соответствующий объект в моделируемой многопроцессорной системе. Как правило, создание и уничтожение объектов осуществляется соответствующими конструкторами и деструкторами экстраполятора времени (RATER).
Функция:
| crtps_ | - создание подсистемы заданной многопроцессорной системы. |
Ввиду того, что пуск подзадачи осуществляется вызовом
long runam_ (AMRef *AMRefPtr)
где *AMRefPtr - ссылка на абстрактную машину запускаемой подзадачи,
а завершение выполнения (останов) текущей подзадачи – вызовом
stopam_ ()
в Предикторе поддерживается стек пар (AM, PS) (где runam_ приводит к загрузке стека парой (AM, PS), а stopam_ - к выгрузке). Вершиной стека определяется текушее состояние системы: текушая АМ и текущая PS. Исходное состояние стека определяет корневые AM и PS (rootAM, rootPS).
Создание пары (AM, PS) осуществляется при интерпретации вызова
mapam_ (AMRef *AMRefPtr, PSRef *PSRefPtr ).
При вызове runam_ топология PS, на которую отображается соответствующая АМ, считывается из конфигурационного файла Предиктора (Predictor.par). АМ нужна Предиктору только для того, чтобы установить текущую PS. Характеристики и топология исходной PS выбираются из трассы (по вызовам crtps_ и psview_ - нужны AMRef, PSRef).
Вызов getamr_ имеет параметр:
IndexArray - массив, i-й элемент которого содержит значение индекса опрашиваемого элемента (т.е. абстрактной машины) по измерению i+1. Для Предиктора важно только лишь то, что создается новая АМ, которая в дальнейшем отображается на вновь созданную PS.
Алгоритм моделирования: на основе информации, считанной из файла параметров, создается объект класса VM (конструктор VM::VM(long ARank, long* ASizeArray, int AMType, double ATStart, double ATByte)). Ссылка на этот объект, а также возвращаемый функцией параметр PSRef, запоминаются в структуре описания МПС.
Функция:
| crtamv_ | - создание представления абстрактной машины. |
Алгоритм моделирования: на основе записанных в трассировке параметров Rank и SizeArray[] создается объект класса AMView (конструктор AMView::AMView(long ARank, long* ASizeArray)). Ссылка на этот объект, а также входной параметр AMRef и возвращаемый функцией параметр AMViewRef, запоминаются в новом элементе массива представлений абстрактных машин.
Функция:
| crtda_ | - создание распределенного массива. |
Алгоритм моделирования: на основе записанных в трассировке параметров Rank, SizeArray[] и TypeSize создается объект класса DArray (конструктор DArray::DArray(long ARank, long* ASizeArray, long ATypeSize)). Ссылка на этот объект, а также возвращаемый функцией параметр ArrayHandlePtr, запоминаются в новом элементе массива распределенных массивов.
Функция:
| crtrg_ | - создание редукционной группы. |
Алгоритм моделирования: создается объект класса RedGroup (конструктор RedGroup::RedGroup(VM* AvmPtr)). В качестве параметра AvmPtr передается ссылки на объект класса VM, созданный в процессе моделирования функции crtps_. Ссылка на созданный объект, а также возвращаемый функцией параметр RedGroupRef, запоминаются в новом элементе массива редукционных групп.
Функция:
| crtred_ | - cоздание редукционной переменной. |
Алгоритм моделирования: создается объект класса RedVar (конструктор RedVar::RedVar(long ARedElmSize, long ARedArrLength, long ALocElmSize)). Параметры ARedArrLength и ALocElmSize берутся из параметров вызова функции, а параметр ARedElmSize вычисляется исходя из параметра вызова RedArrayType по следующей таблице:
| RedArrayType | Тип языка C | ARedElmSize |
| 1 (rt_INT) | int | sizeof(int) |
| 2 (rt_LONG) | long | sizeof(long) |
| 3 (rt_FLOAT) | float | sizeof(float) |
| 4 (rt_DOUBLE) | double | sizeof(doble) |
Ссылка на созданный объект, а также возвращаемый функцией параметр RedRef, запоминаются в новом элементе массива редукционных переменных.
Функция:
| crtshg_ | - cоздание группы границ. |
Алгоритм моделирования: создается объект класса BoundGroup (конструктор BoundGroup::BoundGroup()). Ссылка на созданный объект, а также возвращаемый функцией параметр ShadowGroupRef, запоминаются в новом элементе массива групп границ.
Функция:
| delamv_ | - уничтожение представления абстрактной машины. |
Алгоритм моделирования: в массиве представлений абстрактных машин ищется элемент с ключом AMViewHandlePtr (AMViewRef). Если элемент найден, уничтожается созданный в процессе моделирования функции crtamv_ объект класса AMView, после чего данный элемент удаляется из массива.
Функция:
| delda_ | - уничтожение распределенного массива. |
Алгоритм моделирования: в массиве распределенных массивов ищется элемент с ключом ArrayHandlePtr. Если элемент найден, уничтожается созданный в процессе моделирования функции crtda_ объект класса DArray, после чего данный элемент удаляется из массива.
Функции:
| delred_ | - уничтожение редукционной переменной; |
| delrg_ | - уничтожение редукционной группы. |
Алгоритм моделирования: в массиве редукционных переменных (редукционных групп) ищется элемент с ключом RedRef (RedGroupRef). Если элемент найден, уничтожается созданный в процессе моделирования объект класса RedVar (RedGroup), после чего элемент удаляется из массива.
Функция:
| delshg_ | - уничтожение группы границ. |
Алгоритм моделирования: в массиве групп границ ищется элемент с ключом ShadowGroupRef. Если элемент найден, уничтожается созданный в процессе моделирования объект класса BoundGroup, после чего элемент удаляется из массива.
3.6 Функции распределения ресурсов и данных
В данную группу входят функции, осуществляющие начальное распределение и перераспределение ресурсов и данных.
Функция:
| distr_ | - | задание отображения представления абстрактной машины на многопроцессорную систему (распределение ресурсов). |
Алгоритм моделирования: в массиве представлений абстрактных машин ищется элемент с ключом AMViewRef. Если элемент найден, вызывается метод AMView::DisAM(VM *AVM_Dis, long AParamCount, long* AAxisArray, long* ADistrParamArray). В качестве параметра AVM_Dis передается ссылки на объект класса VM, созданный в процессе моделирования функции crtps_, остальные параметры соответствуют параметрам вызова функции.
Функция:
| align_ | - задание расположения (выравнивание) pаспределенного массива. |
Алгоритм моделирования: в массиве распределенных массивов ищется элемент с ключом ArrayHandlePtr. В зависимости от типа образца выравнивания (AMView или DisArray), в массиве представлений абстрактных машин или в массиве распределенных массивов ищется элемент с ключом PatternRef. Для объекта класса DArray из найденной в массиве распределенных массивов записи с ключом ArrayHandlePtr вызывается метод DArray::AlnDA(AMView*{DArray*} APattern, long* AAxisArray, long* ACoeffArray, long* AConstArray). В качестве первого параметра передается ссылка на объект типа AMView или DArray, в зависимости от типа образца, соответствующий ключу PatternRef. Остальные параметры извлекаются из параметров вызова функции. Кроме этого, запоминается тип образца выравнивания. При моделировании игнорируется пересылка данных в процессе выравнивания распределенного массива.
Функция:
| redis_ | - | изменение отображения представления абстрактной машины на многопроцессорную систему (перераспределение ресурсов). |
Алгоритм моделирования: в массиве представлений абстрактных машин ищется элемент с ключом AMViewRef. Для объекта класса AMView из найденной в массиве представлений абстрактных машин записи вызывается метод AMView::RDisAM(long AParamCount, long* AAxisArray, long* ADistrParamArray, long ANewSign). Параметры извлекаются из параметров вызова функции.
Алгоритм моделирования времени отличается от основного. Сначала счетчики времени всех процессоров приводятся к одному значению, равному максимальному из значений счетчиков на момент начала выполнения redis_. Время, которое было добавлено к счетчику, прибавляется к Execution_Time и к Synchronization данного процессора. Время, возвращенное методом AMView::RDisAM(…), прибавляется к Execution_time и к Redistribution каждого процессора. После этого работа функции считается завершенной.
Функция:
| realn_ | - изменение расположения распределенного массива. |
Алгоритм моделирования: в массиве распределенных массивов ищется элемент с ключом ArrayHandlePtr. В зависимости от типа нового образца выравнивания (AMView или DisArray), в массиве представлений абстрактных машин или в массиве распределенных массивов ищется элемент с ключом PatternRef. Для объекта класса DArray из найденной в массиве распределенных массивов записи с ключом ArrayHandlePtr вызывается метод DArray::RAlnDA(AMView*{DArray*} APattern, long* AAxisArray, long* ACoeffArray, long* AConstArray, long ANewSign). В качестве первого параметра передается ссылка на объект типа AMView или DArray, в зависимости от типа образца, соответствующий ключу PatternRef. Остальные параметры извлекаются из параметров вызова функции. Запоминается тип нового образца выравнивания. Если параметр NewSign равен 1, ищется вложенный вызов функции crtda_ и ключ массива заменяется новым значением, полученным как выходной параметр ArrayHandlePtr функции crtda_. Алгоритм моделирования времени отличается от основного. Сначала счетчики времени всех процессоров приводятся к одному значению, равному максимальному из значений счетчиков на момент начала выполнения realn_. Время, которое было добавлено к счетчику, прибавляется к Execution_Time и к Synchronization данного процессора. Время, возвращенное методом DArray::RAlnDA(…), прибавляется к Execution_time и к Redistribution каждого процессора. После этого работа функции считается завершенной.
3.7 Функции инициализации коллективных операций
В данную группу входят функции, осуществляющие вставку редукционной переменной в редукционную группу и вставку границ распределенного массива в группу границ.
Функция:
| insred_ | - включение редукционной переменной в редукционную группу. |
Алгоритм моделирования: в массиве редукционных переменных ищется элемент с ключом RedRef и соответствующий ему объект класса RedVar; в массиве редукционных групп ищется элемент с ключом RedGroupRef и соответствующий ему объект класса RedGroup. Вызывается метод RedGroup::AddRV(RedVar* ARedVar) для найденного объекта класса RedGroup с найденным объектом класса RedVar в качестве параметра.
Функция:
| inssh_ | - включение границы распределенного массива в группу границ. |
Алгоритм моделирования: в массиве групп границ ищется элемент с ключом ShadowGroupRef и соответствующий ему объект класса BoundGroup; в массиве распределенных массивов ищется элемент с ключом ArrayHandlePtr и соответствующий ему объект класса DArray. Вызывается метод BoundGroup::AddBound(DArray* ADArray, long* ALeftBSizeArray, long* ARightBSizeArray, long ACornerSign) для найденного объекта класса BoundGroup. В качестве первого параметра передается ссылка на найденный объект класса DArray; параметру ALeftBSizeArray соответствует входной параметр LowShdWidthArray функции inssh_, параметру ARightBSizeArray – параметр HiShdWidthArray, параметру ACornerSign – параметр FullShdSign.
3.8 Функции выполнения коллективных операций
В данную группу входят функции, осуществляющие выполнение коллективных операций.
Функция:
| arrcpy_ | - копирование распределенных массивов. |
Алгоритм моделирования: в массиве распределенных массивов ищутся элементы с ключами FromArrayHandlePtr и ToArrayHandlePtr. Выполняется функция ArrayCopy(DArray* AFromArray, long* AFromInitIndexArray, long* AFromLastIndexArray, long* AFromStepArray, DArray* AToArray, long* AToInitIndexArray, long* AToLastIndexArray, long* AToStepArray, long ACopyRegim). В качестве параметров ей передаются указатели на объекты класса DArray из найденных записей и параметры FromInitIndexArray[], FromLastIndexArray[], FromStepArray[], ToInitIndexArray[], ToLastIndexArray[], ToStepArray[], CopyRegim из вызова функции arrcpy_.
Алгоритм моделирования времени отличается от основного. Сначала счетчики времени всех процессоров приводятся к одному значению, равному максимальному из значений счетчиков на момент начала выполнения arrcpy_. Время, которое было добавлено к счетчику, прибавляется к Execution_Time и к Synchronization данного процессора. Время, возвращенное функцией ArrayCpy(…), прибавляется к Execution_time и к Remote_access каждого процессора. После этого работа функции считается завершенной.
Функция:
| strtrd_ | - запуск редукционной группы. |
Алгоритм моделирования: в массиве редукционных групп ищется элемент с ключом RedGroupRef. Для объекта класса RedGroup из найденного элемента вызывается метод RedGroup::StartR(DArray* APattern, long ALoopRank, long* AAxisArray). Параметры APattern, ALoopRank и AAxisArray берутся из структуры, которая была заполнена при последнем вызове функции mappl_ и соответствуют последнему отображенному параллельному циклу. Создается элемент с ключом RedGroupRef в массиве стартовавших редукций. В этом элементе сохраняется время начала редукции, равное максимальному из значений счетчиков процессоров на момент вызова функции strtrd_ и время окончания редукции, равное сумме времени начала редукции и времени, возвращенного методом RedGroup::StartR(…). В случае, если образцом для отображения параллельного цикла послужил не распределенный массив, а представление абстрактной машины, фиксируется ошибка и моделирование прекращается.
Алгоритм моделирования времени отличается от основного. Сначала счетчики времени всех процессоров приводятся к одному значению, равному максимальному из значений счетчиков на момент начала выполнения strtrd_. Время, которое было добавлено к счетчику, прибавляется к Execution_Time и к Synchronization данного процессора.
Функция:
| strtsh_ | - запуск обмена границами заданной группы. |
Алгоритм моделирования: в массиве групп границ ищется элемент с ключом ShadowGroupRef. Для объекта класса BoundGroup из найденного элемента вызывается метод BoundGroup::StartB(). Создается элемент с ключом ShadowGroupRef в массиве стартовавших обменов границами. В этом элементе сохраняется время начала обменов, равное максимальному из значений счетчиков процессоров на момент вызова функции strtsh_ и время окончания обменов, равное сумме времени начала обменов и времени, возвращенного методом BoundGroup::StartB().
Алгоритм моделирования времени отличается от основного. Сначала счетчики времени всех процессоров приводятся к одному значению, равному максимальному из значений счетчиков на момент начала выполнения strtsh_. Время, которое было добавлено к счетчику, прибавляется к Execution_Time и к Synchronization данного процессора.
Функция:
| waitrd_ | - ожидание завершения редукции. |
Алгоритм моделирования: в массиве стартовавших редукций ищется элемент с ключом RedGroupRef. По окончании моделирования данный элемент удаляется из массива.
Алгоритм моделирования времени отличается от основного. Для каждого процессора сравнивается текущее значение счетчика времени и время окончания редукции, зафиксированное в процессе моделирования функции strtrd_, при этом разница времен прибавляется к Reduction_overlap. Если значение счетчика времени процессора меньше, чем время окончания редукции, то значение счетчика приводится к времени окончания редукции, при этом время, которое было добавлено к счетчику, прибавляется к Execution_Time и к Reduction_wait данного процессора. После этого работа функции считается завершенной.
Функция:
| waitsh_ | - ожидание завершения обмена границами заданной группы. |
Алгоритм моделирования: в массиве стартовавших обменов границами ищется элемент с ключом ShadowGroupRef. По окончании моделирования данный элемент удаляется из массива.
Алгоритм моделирования времени отличается от основного. Для каждого процессора сравнивается текущее значение счетчика времени и время окончания обменов, зафиксированное в процессе моделирования функции strtsh_, при этом разница времен прибавляется к Shadow_overlap. Если значение счетчика времени процессора меньше, чем время окончания обменов, то значение счетчика приводится к времени окончания обменов, при этом время, которое было добавлено к счетчику, прибавляется к Execution_Time и к Wait_shadow данного процессора. После этого работа функции считается завершенной.
3.9 Функции организации параллельного цикла
В данную группу входят функции, осуществляющие инициализацию параллельного цикла, распределение его витков между процессорами и его выполнение.
Функция:
| crtpl_ | - создание параллельного цикла. |
Алгоритм моделирования: в структуру, описывающую параллельный цикл, записывается параметр Rank – размерность параллельного цикла.
Функция:
| mappl_ | - отображение параллельного цикла. |
Алгоритм моделирования: создается объект класса ParLoop (конструктор ParLoop:: ParLoop (long ARank)). Метод ParLoop::MapPL(AMView*{DArray*} APattern, long* AAxisArray, long* ACoeffArray, long* AconstArray, long* AInInitIndex, long* AInLastIndex, long* AInLoopStep) моделирует распределение витков параллельного цикла по процессорам. Далее, для каждого процессора строится объект, соответствующий блоку витков цикла, отображенному на данный процессор (конструктор LoopBlock::LoopBlock(ParLoop *pl, long ProcLI)). Кроме того, в структуре, описывающей параллельный цикл, запоминается ключ образца отображения (PatternRef) и его тип.
Функция:
| dopl_ | - опрос необходимости продолжения выполнения параллельного цикла. |
Алгоритм моделирования: Алгоритм моделирования времени отличается от основного. Вычисляется и запоминается общее количество витков цикла (Nвитков) и количество витков цикла на каждом процессоре (Ni). Для каждого процессора вычисляется величина Тфунк*(Ni/Nвитков) и прибавляется к Execution_time и CPU_time данного процессора. Кроме того, область вычислений процессора сравнивается с областями вычислений других процессоров, вычисляется число процессоров, выполнявших одинаковые витки цикла (Nпроц), потом для каждого процессора, выполнявшего данную часть цикла, вычисляется величина
(Тфунк/Ni)*((Nпроц-1)/Nпроц)
и прибавляется к Insufficient_parallelism_Par.
Алгоритм моделирования: неизвестные функции моделируются по основному алгоритму. При этом выдается предупреждение о встрече в трассировке неизвестной функции с указанием ее названия.
4 Оценка накладных расходов доступа к удаленным данным
4.1 Основные понятия и термины
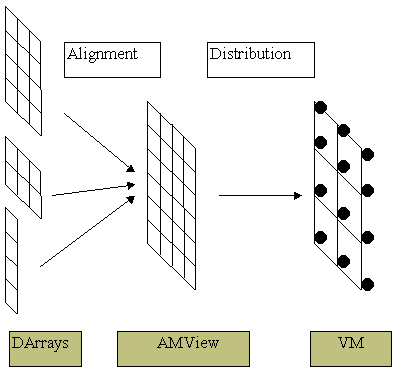
Прежде чем переходить к описанию используемых алгоритмов оценки накладных расходов доступа к удаленным данным, необходимо сказать несколько слов о том, как происходит отображение вычислений и данных на распределенную систему. На рис.1 изображена диаграмма распределения массивов по процессорной топологии в DVM модели.
Рис.1. DVM-модель распределения данных по процессорам.
Вводится понятие Представление абстрактной машины (в дальнейшем для краткости будем использовать синонимы данного термина – Шаблон или AMView) – специального массива, предназначенного для обеспечения двухступенчатого отображения массивов и вычислений на систему процессоров: сначала они (Darrays) отображаются на AMView, которая затем отображается на систему процессоров (VM). Первое отображение целиком определяется взаимосвязями вычислений и данных, свойственными алгоритму, и не зависит от архитектуры и конфигурации распределенной вычислительной системы. Второе отображение служит для настройки параллельной программы на предоставляемые ей ресурсы конкретной ЭВМ.
При выполнении выравнивания или повторного выравнивания распределенного массива в качестве AMView может также выступать и обычный распределенный массив, уже отображенный на некоторую AMView (косвенное задание отображения).
Задание информации о выравнивании массивов на шаблон осуществляется при помощи вызова функции DArray::AlnDA. Распределение шаблона на систему процессоров производится путем вызова функции AMView::DisAM.
4.2 Оценка обменов при перераспределении массивов
Рассмотрим алгоритм определения накладных расходов при повторном выравнивании массива на шаблон (realign). Данный алгоритм реализуется функцией DArray::RAlnDA, которая возвращает время затрачиваемое на обмены между процессорами при выполнении указанной выше операции. Кроме этого функция изменяет для данного массива информацию о том, на какой шаблон он отображен и по какому правилу, в соответствии с указанными при обращении к функции параметрами. Производится корректировка списков выровненных массивов для соответствующих шаблонов.
Алгоритм
начинается с того, что мы проверяем
значение входного параметра ANewSign. При его не нулевом
значении содержимое вновь
выровненного массива будет
обновлено, следовательно, нет
необходимости пересылать заведомо
не нужные элементы, а значит
возвращаемое значение в этом
случае равно нулю. Если это не так,
то алгоритм продолжает свою работу.
Сохраняем информацию о том, как был
расположен массив до повторного
выравнивания, и при помощи
вспомогательной функции DArray::AlnDA определяем информацию
о его новом расположении после
выполнения данной операции.
Затем, при помощи функции CommCost::Update(DArray
*, DArray *),
производится изменение массива CommCost::transfer (инициализирован в
начале нулями), содержащего
информацию о числе байтов
пересылаемых между двумя любыми
процессорами, основываясь на
информации о расположении массива
до и после повторного выравнивания,
полученной выше.
В конце определяем искомое время по
полученному массиву transfer, используя функцию CommCost::GetCost.
Теперь опишем алгоритм, реализуемый функцией Update:
1. На вход
поступает информация о
распределении массива до и после
выполнения операции (назовем ее
перераспределением массива)
меняющей расположение массива.
Вначале проверяем, был ли массив
полностью размножен по шаблону до
перераспределения (оформление
этого признака производится во
вспомогательной функции DArray::AlnDA). Пусть это так, иначе
переходим к пункту 2. Если множество
процессоров (обозначим его М1), на
которых были расположены элементы
шаблона до перераспределения
массива, содержит в себе множество
процессоров (обозначим его М2), на
которых расположены элементы
шаблона после перераспределения,
то пересылок нет, следовательно,
массив transfer не
изменяется и алгоритм заканчивает
свою работу. В противном случае для
каждого процессора (обозначим его
П2) принадлежащего разности
множеств М2 и М1 находим ближайший к
нему процессор (обозначим его П1) из
множества М1 (он лежит на границе
прямоугольной секции образованной
процессорами принадлежащими
множеству М1). Далее для каждой
такой пары процессоров выполняем
ниже описанные действия. Для
процессора П2 находим
принадлежащую ему после
перераспределения секцию массива,
используя конструктор Block::Block(DArray
*, long). Секция
массива, располагавшаяся на
процессоре П1 до выполнения
операции, совпадает со всем
массивом, т.к. тот был полностью
размножен по шаблону. Взяв
пересечение этих двух секций,
используя operator ^ (Block &, Block
&), мы получаем
секцию подлежащую пересылке с
процессора П1 на процессор П2.
Определив число байтов в ней,
воспользовавшись функцией Block::GetBlockSize, добавляем его к
соответствующему элементу массива transfer. Алгоритм заканчивает
свою работу.
Определяем все измерения системы
процессоров, по которым размножен
или частично размножен массив до
перераспределения. Если таких
измерений не имеется, то переходим
к пункту 3.
Для измерений системы процессоров,
по которым массив частично
размножен, определяем множества
значений индексов, при которых на
соответствующих процессорах
имеются элементы массива до
перераспределения. Обходим все
процессоры (обозначим текущий как
П1) чьи индексы в измерениях, по
которым размножен массив, равны
нулю, а в тех измерениях, по которым
массив частично размножен, равны
минимумам из соответствующих
полученных множеств.
2. Определяем для этих процессоров секции массива находившиеся на них до перераспределения. Для всех процессоров (обозначим текущий как П2) определяем секции массива, которые расположены на них после перераспределения. Находим пересечение выше описанных секций для текущих процессоров П1 и П2. Для процессора П2 определяем ближайший к нему процессор, секция массива на котором совпадает с секцией на процессоре П1. Индексы этого процессора по всем измерениям системы процессоров совпадают с соответствующими индексами процессора П1 за исключением индексов по измерениям, по которым массив размножен или частично размножен. По этим измерениям индексы берутся наиболее близкими к соответствующим индексам процессора П2 (определяются используя полученные выше множества). Если номер полученного процессора не совпадает с номером П2, то в соответствующий элемент массива transfer добавляем число байтов в найденном выше пересечении. После обработки всех пар процессоров (П1, П2), алгоритм завершает свою работу.
3. Для каждого процессора определяем секцию массива расположенную на нем до перераспределения. Также для каждого процессора определяем секцию массива расположенную на нем после перераспределения. Находим пересечение таких секций, для каждой пары не совпадающих процессоров. Число байтов в пересечении добавляем к элементу массива transfer, соответствующему данной паре процессоров. После обработки всех таких пар процессоров, алгоритм завершает свою работу.
В функции GetCost, для нахождения времени затрачиваемого на обмены между процессорами, используется один из двух алгоритмов – в зависимости от типа распределенной системы процессоров. В случае сети с шинной организацией искомое время определяется по следующей формуле:
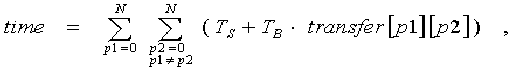
где N – число процессоров, Ts – время старта операции обмена, TB – время пересылки одного байта. Эта формула следует из того, что в сети не может одновременно находится несколько сообщений и, следовательно, общее время равно сумме всех времен обменов между двумя любыми не совпадающими между собой процессорами.
Для транспьютерной решетки общее время в основном зависит от расстояния (кратчайшего пути) между двумя наиболее удаленными друг от друга процессорами, между которыми существуют обмены. Также при оценке этого времени для данного типа системы необходимо учесть возможность конвейеризации сообщений. Исходя из этих замечаний, получаем следующий алгоритм и формулу для определения накладных расходов:
![]()
Если l > 1, то возможна конвейеризация сообщения. Поэтому вначале исследуем на экстремум следующую функцию, описывающую зависимость времени пересылки сообщения размера LB от размера S сообщения пересылаемого за одну фазу конвейера:
Получим, что минимум данной функции достигается при
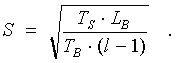
С учетом того, что размер сообщения пересылаемого за одну фазу конвейера и число фаз – целые числа, мы приходим к следующему выражению:
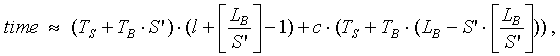
где S’ = [S] (S’ = 1, если [S] = 0); c I {0, 1} – признак того, что LB не делится нацело на S’. Для нахождения точного значения определим время по этой же формуле, но в соседних с S’ целочисленных точках. Если они больше, то найденное в точке S’ значение является искомым. Иначе производим поиск в направлении убывания, пока на некотором шаге k не получим значения большего чем на шаге k–1. Тогда искомым временем будет являться значение, полученное на k–1 шаге. Алгоритм завершает свою работу.
В заключение данного параграфа рассмотрим алгоритм нахождения накладных расходов при перераспределении шаблона. Эти расходы возникают в связи с тем, что все распределенные массивы, ранее выровненные по рассматриваемому шаблону с помощью функции DArray::AlnDA (как непосредственно, так и косвенно), будут отображены заново по прежним правилам выравнивания на этот шаблон после того, как он поменяет свое расположение на системе процессоров, следовательно, и они поменяют свое расположение, что приведет к обменам. Данный алгоритм реализуется функцией AMView::RDisAM, которая возвращает время затрачиваемое на выполнение обменов между процессорами при выполнении данной операции. Также функция изменяет для данного шаблона информацию о том, по какому правилу он был отображен в систему процессоров (установленную ранее с помощью функции AMView::DisAM), на информацию о его новом распределении в соответствии с параметрами указанными при обращении к функции.
Алгоритм начинается с того, что мы проверяем значение входного параметра ANewSign. Если он не равен нулю, то это означает, что содержимое всех распределенных массивов, ранее выровненных по рассматриваемому шаблону, будет обновлено, следовательно, нет необходимости пересылать заведомо не нужные элементы, а значит возвращаемое значение в этом случае равно нулю. Если это не так, то алгоритм продолжает свою работу.
Затем, предварительно сохранив информацию о том, как был распределен шаблон до перераспределения, определяем при помощи вспомогательной функции AMView::DisAM информацию о его распределении после выполнения данной операции. Это нужно для того, чтобы знать, как расположены выровненные по данному шаблону массивы до и после перераспределения.
Далее для каждого массива, выровненного по рассматриваемому шаблону, при помощи функции CommCost::Update(DArray *, DArray *), производится изменение массива CommCost::transfer (инициализирован в начале нулями), основываясь на информации о расположении массива до и после повторного выравнивания, полученной выше.
В конце определяем искомое время по полученному массиву transfer, используя функцию CommCost::GetCost.
4.3 Оценка обменов границами распределенных массивов
Рассмотрим алгоритм вычисления времени затрачиваемого на обмен границами заданной группы. Он состоит из двух частей:
Алгоритм, реализуемый функцией CommCost::GetCost, был описан в предыдущем параграфе, поэтому остановимся на алгоритме функции BoundGroup::AddBound:
4.4 Оценка обменов при выполнении операций редукции
Алгоритм определения времени затрачиваемого на обмены при выполнении операций редукции реализован в функции RedGroup::StartR, но прежде чем перейти к его описанию покажем, какая предварительная работа производится.
При добавлении очередной редукционной переменой к редукционной группе при помощи функции RedGroup::AddRV производится увеличение счетчика числа пересылаемых при запуске редукционной группы байтов - TotalSize на величину равную размеру в байтах редукционной переменой и дополнительной информации, сопровождающей редукционную операцию (задается для некоторых редукционных операций). Информация же о типе редукционной операции при оценке обменов возникающих при ее выполнении не важна.
Описание функции StartR:
time = (TS + TB * TotalSize) * (Ni1 * ... * Nik + N – 2) ,
где N – число процессоров, Ts – время старта операции обмена, TB – время пересылки одного байта, Nik – число процессоров по измерению системы процессоров с номером loopAlign[ik], на которых присутствуют витки цикла. Функция возвращает полученное значение.
time = (TS + TB * TotalSize) * (2 * Distance + ConerDistance),
где ConerDistance – расстояние от данных секций до наиболее удаленного углового процессора. Возвращаем полученное значение.
4.5 Оценка обменов при загрузке буферов удаленными элементами массивов
Если выравниванием массивов не удается избавиться от удаленных данных и для доступа к ним нельзя использовать теневые грани, то их буферизация на каждом процессоре осуществляется через отдельный буферный массив. Оценка времени затрачиваемого на обмены при загрузке этих буферов производится в функции ArrayCopy. Интерфейс данной функции рассчитан на дальнейшее расширение выходного языка, поэтому часть параметров на данном этапе не используется. Если говорить более конкретно, то в данной функции оцениваются обмены при размножении секции распределенного массива (читаемый массив) по всем процессорам системы. Ниже приводится описание алгоритма реализуемого функцией ArrayCopy:
В функции CopyUpdate выполняется следующая последовательность действий: