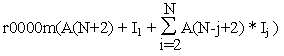
Компилятор Fortran-DVM |
Оглавление
1 Функции компилятора
2 Состав компилятора
3 Принципы реализации
4 Трансляция FDVM программы
4.1 Распределенные массивы
4.2 Трансляция директив спецификации
4.2.1 Директива PROCESSORS
4.2.2 Директивы отображения данных
4.2.3 Директива TASK
4.2.4 Директивы REMOTE_GROUP и REDUCTION_GROUP
4.3.1 Директива PARALLEL
4.3.2 Директивы PREFETCH и RESET
4.3.3 Директива MAP
4.3.4 Конструкция TASK_REGION
4.3.5 Конструкция параллельного цикла по задачам
4.3.6 Другие директивы FDVM
4.3.7 Директивы отладки
4.3.8 Операторы ввода-вывода
5 Трансляция HPF-DVM программы
5.1 Оператор присваивания и другие исполняемые операторы вне цикла INDEPENDENT
5.2 Директива INDEPENDENT
Язык Fortran DVM (FDVM) является расширением языка Фортран 77 для параллельного программирования. Расширение оформлено в виде специальных комментариев (директив DVM), которые аннотируют последовательную программу на языке Фортран 77.
Компилятор транслирует параллельную FDVM программу в программу на языке Фортран 77 с вызовами функций системы поддержки параллельного выполнения (Lib-DVM). Система поддержки Lib-DVM написана на языке C и использует средства MPI для обеспечения межпроцессорного взаимодействия.
По требованию пользователя компилятор FDVM генерирует расширенный код для отладки и анализа производительности. Специальный режим компиляции предназначен для генерации “последовательной” программы, игнорируя директивы DVM.
Компилятор FDVM транслирует также программы, написанные на языке HPF-DVM, который является подмножеством HPF.
Процесс компиляции состоит из трех фаз.
Сначала производится синтаксический анализ программы на исходном языке и формируется ее внутреннее представление (.dep файл), которое состоит из дерева грамматического разбора, таблицы символов и таблицы типов.
Вторая фаза предполагает анализ и реструктурирование внутреннего представления FDVM программы. Каждая директива DVM заменяется последовательностью обращений к функциям системы поддержки Lib-DVM. На этой фазе осуществляются следующие действия:
При этом может потребоваться реструктурирование графа управления, когда новый оператор включается в программу (перемещение и замена меток, замена оператора логический IF конструкцией IF...THEN...ENDIF и т.п.).
Третья фаза – это генерация кода на Фортране 77, соответствующего ре-структурированному внутреннему представлению.
В качестве инструментального средства разработки компилятора FDVM используется система Sage++.
Синтаксический анализатор системы Sage++ для Фортрана, который базируется на GNU Bison версии языка YACC, расширен средствами обработки директив DVM.
Программа “back-end” написана на языке C++ с использованием библиотеки классов Sage++. Она просматривает программу в лексическом порядке и заменяет каждую директиву DVM последовательностью вызовов функций Lib-DVM.
Генерация нового кода на Фортране 77 осуществляется посредством функции unparse( ) класса File из библиотеки классов Sage++.
Массив с атрибутом DISTRIBUTE или ALIGN называется распределенным массивом. Память для элементов таких массивов отводится системой поддержки Lib-DVM. Система поддержки отводит память на каждом процессоре для локальной секции массива в соответствии с форматом распределения массива, заданным директивой DISTRIBUTE, и для теневых граней, объявленных в директиве SHADOW.
Распределенный массив адресуется относительно базы, объявляемой посредством операторов:
integer i0000m(0:0)
common /mem000/ i0000m
real r0000m(0:0)
equivalence (i0000m,r0000m)
Коэффициенты адресации и смещение вычисляется функцией системы поддержки (align()) и запоминается в дескрипторе распределенного массива, называемом заголовком массива. Память для заголовка массива отводится в программе пользователя. Компилятор FDVM удаляет из программы пользователя описание распределенного массива и включает в нее описание заголовка массива как одноименного целочисленного вектора из 2*N+2+NR элементов, где N – размерность массива, а NR – число слов памяти, отводимой для заголовков буферов удаленных данных. Так например, если A является распределенным массивом, то оператор описания
real A(L1:U1,L2:U2,...,LN:UN)
заменяется оператором
integer A(2*N+2+NR)
Компилятор линеаризует каждую ссылку на элемент распределенного массива
A(I1,I2, ..., IN)
заменяя ее выражением
Структура заголовка массива приводится на Рис.1.
| 1 | указатель на структуру Lib-DVM | |
| 2 | C1 | коэффициенты |
| 3 | C2 | адресации |
| . . . | элементов | |
| N+1 | CN | массива |
| N+2 | смещение | |
| N+3 | L1 | нижние |
| N+4 | L2 | границы |
| . . . | измерений | |
| 2*N+2 | LN | массива |
| 2*N+3 | счетчик удаленных ссылок | |
| память для | ||
| . . . | заголовков буферов | |
| удаленных данных |
Рис.1. Структура заголовка массива в FDVM.
Первые N+2 элемента заголовка инициализируются функцией системы поддержки align( ) и обновляются функциями realn( ) и redis( ). Для запоминания значений нижних границ измерений массива компилятор вставляет операторы присваивания в программу пользователя.
4.2 Трансляция директив спецификации
4.2.1 Директива PROCESSORS
Директива PROCESSORS описывает виртуальную систему процессоров. Директива
*DVM$ PROCESSORS P(NP1,…,NPr)
заменяется оператором
INTEGER P
А также, в программу включается (непосредственно перед первым исполняемым оператором) следующий сегмент операторов:
* получение вектора размеров измерений процессорной системы
size(1) = NP1
. . .
size(r) = NPr
* создание процессорной системы
P = psview(ps,r,size,0)
Ссылки на функции NUMBER_OF_PROCESSORS ( ) и ACTIVE_NUM_PROCS( ) заменяются ссылками на функцию Lib-DVM
getsiz(getps(-1),0) и getsiz(getps(0), 0)
соответственно.
4.2.2 Директивы отображения данных
Директивы спецификации DISTRIBUTE, ALIGN и TEMPLATE определяют дерево отображения распределенных массивов. Анализируя директивы спецификации, компилятор FDVM строит деревья отображения и генерирует операторы для создания распределенных массивов:
Например, следующие директивы
REAL A(100), B(100), C(100,100), D(100) *DVM$ TEMPLATE T(100,100) *DVM$ DISTRIBUTE T (BLOCK, BLOCK) *DVM$ ALIGN A(I) WITH T(I,*) *DVM$ ALIGN B(I) WITH T(*,I) *DVM$ DISTRIBUTE C (BLOCK, BLOCK) *DVM$ DISTRIBUTE D (GEN_BLOCK(NB)) ONTO P
задают следующее дерево выравниваний:
A B \ / T
Для создания распределенного объекта генерируется следующая последовательность операторов:
* получение вектора размеров измерений шаблона size(1) = размер-N-ого-измерения . . . size(N) = размер-1-ого-измерения * создание представления абстрактной машины iamv = crtamv(am,N,size,...) * отображение представления абстрактной машины на процессорную систему it = distr(iamv,ps,...)где:
am – ссылка на текущую абстрактную машину,
ps– ссылка на текущую процессорную систему.
* запоминание нижних границ измерений распределенного массива
* в его заголовке
A(N+3) = L1
. . .
A(2*N) = LN
* создание распределенного массива
it = crtda(A,i0000m,N,...)
. . .
* выравнивание (отображение) распределенного массива
it = align(A,iamvt,N,...)
* получение вектора размеров измерений массива
size(1) = размер-N-ого-измерения
. . .
size(N) = размер-1-ого-измерения
* создание представления абстрактной машины
iamv = crtamv(am,N,size,...)
* отображение представления абстрактной машины на процессорную систему
it = distr(iamv,ps,...)
* запоминание нижних границ измерений распределенного массива
* в его заголовке
C(N+3) = L1
. . .
C(2*N) = LN
* создание распределенного массива
it = crtda(C,i0000m,N,...)
. . .
* выравнивание (отображение) распределенного массива
it = align(C,iamv,N,...)
* получение вектора размеров измерений массива
size(1) = размер-N-ого-измерения
. . .
size(N) = размер-1-ого-измерения
* создание представления абстрактной машины
iamv = crtamv(am,N,size,...)
* установка весов элементов процессорной системы
it = genbli(ps,iamv,NB,…)
* отображение представления абстрактной машины на процессорную систему
it = distr(iamv,ps,...)
* запоминание нижних границ измерений распределенного массива
* в его заголовке
C(N+3) = L1
. . .
C(2*N) = LN
* создание распределенного массива
it = crtda(D,i0000m,N,...)
. . .
* выравнивание (отображение) распределенного массива
it = align(D,iamv,N,...)
Операторы для создания распределенных объектов вставляются в программную единицу перед первым исполняемым оператором.
Для динамического массива, адресуемого с помощью переменной POINTER, генерируется такая же последовательность операторов, но она вставляется в программу вместо оператора:
pointer= ALLOCATE(...).
Секция массива HEAP:
HEAP( I : I+header-size-1)
выделяется для размещения заголовка динамического массива. Соответствующей переменной POINTER присваивается значение I.
Объявление пула динамической памяти HEAP удаляется и новый оператор описания генерируется
INTEGER HEAP(S)
где S – суммарный размер заголовков всех объявленных в процедуре динамических массивов.
Отображение массивов, объявленных директивами ALIGN и DISTRIBUTE вида
*DVM$ ALIGN :: D *DVM$ DISTRIBUTE :: E
откладывается до выполнения директив REALIGN и REDISTRIBUTE. Только оператор создания распределенного массива генерируется в начале программной единицы.
4.2.3 Директива TASK
Объект, объявленный в директиве TASK является массивом задач. Директива
*DVM$ TASK TA(M)
заменяется оператором спецификации
INTEGER TA(2,M)
Кроме того, генерируется следующая последовательность операторов, которая вставляется перед первым исполняемым оператором процедуры:
* создание представления абстрактной машины
iamv = crtamv(am,1,M,...)
* запрос ссылок на элементы представления абстрактной машины
DO lab idvm00 = 1,M
lab TA(2,idvm00) = getamr(iamv,idvm00-1)
4.2.4 Директивы REMOTE_GROUP и REDUCTION_GROUP
Имя, объявленное в директиве REMOTE_GROUP, является именем группы удаленных ссылок. Директива
*DVM$ REMOTE_GROUP RMG
заменяется оператором
INTEGER RMG(3)
Если в процедуре встречается директива PREFETCH, тогда следующие операторы инициализации целочисленного массива RMG генерируются и включаются в начало исполняемой части процедуры:
RMG(1) = 0
RMG(2) = 0
RMG(3) = 0
Имя, объявленное в директиве REDUCTION_GROUP, является именем группы редукций. Директива
*DVM$ REDUCTION_GROUP REDG
заменяется оператором
INTEGER REDG
Генерируется оператор присваивания нулевого значения целой переменной REDG:
REDG = 0
Он вставляется в программную единицу перед первым исполняемым оператором.
4.3 Трансляция исполняемых директив и операторов
4.3.1 Директива PARALLEL
Параллельный цикл:
*DVM$ PARALLEL (I1, ..., In) ON A(…)...
DO label I1 = ...
. . .
DO label In = ...
тело-цикла
label CONTINUE
транслируется в последовательность операторов:
[ ACROSS-block-1 ]
[ REDUCTION-block-1 ]
* создание параллельного цикла
ipl = crtpl(n)
[ SHADOW-RENEW-block-1 ]
[ SHADOW-START-block ]
[ SHADOW-WAIT-block ]
* отображение параллельного цикла
it = mappl(ipl,A,...)
[ SHADOW-RENEW-block-2 ]
[ REDUCTION-block-2 ]
[ REMOTE-ACCESS-block ]
* запрос о продолжении выполнения параллельного цикла
lab1 if(dopl(ipl) .eq. 0) go to lab2
DO label I1 = ...
. . .
DO label In = ...
тело-цикла
label CONTINUE
go to lab1
* завершение параллельного цикла
lab2 it = endpl(ipl)
[ ACROSS-block-2 ]
[ REDUCTION-block-3 ]
Если в директиве PARALLEL встречается спецификация REDUCTION, то генерируются блоки операторов REDUCTION-block-1, REDUCTION-block-2 и REDUCTION-block-3.
REDUCTION-block-1:
В случае синхронной спецификации REDUCTION:
* создание группы редукций
irg = crtrg(1,1)
В случае синхронной спецификации REDUCTION (с именем группы RDG):
if(RDG.EQ.0) THEN
* создание группы редукций
RDG = crtrg(1,1)
END IF
{
* создание редукционной переменной
irv = crtrdf(reduction-function, reduction-var,...)
}... для каждой редукции из списка reduction-list
REDUCTION-block-2:
{
* включение редукционной переменной в группу
it = insred(irg,irv,ipl,0)
}... для каждой редукции из списка reduction-list
REDUCTION-block-3:
* запуск выполнения группы редукций
it = strtrd(irg)
* ожидание завершения выполнения редукций группы
it = waitrd(irg)
* уничтожение редукционной группы
it = delobj(irg)
Если в директиве PARALLEL встречается спецификация SHADOW_RENEW, то включаются блоки SHADOW-RENEW-block-1 и SHADOW-RENEW-block-2:
SHADOW-RENEW-block-1:
* создание группы теневых граней
ishg = crtshg(...)
{
* включение теневой грани в группу
it = inssh(ishg,array-header,...)
}... для каждого массива из списка renewee-list
* инициализация обновления теневых граней
it = strtsh(ishg)
SHADOW-RENEW-block-2:
* ожидание завершения обновления теневых граней
it = waitsh(ishg)
Спецификации SHADOW_START и SHADOW_WAIT вызывают изменение порядка выполнения итераций параллельного цикла.
SHADOW-START-block:
it = exfrst(shadow-group-name)
Функция exfrst( ) устанавливает следующий порядок выполнения итераций:
SHADOW-WAIT-block:
it = imlast(shadow-group-name)
Функция imlast( ) устанавливает следующий порядок выполнения итераций:
Если в директиве PARALLEL есть спецификация ACROSS, генерируются блоки ACROSS-block-1 и ACROSS-block-2.
ACROSS-block-1:
* создание группы теневых граней
ishg = crtshg(0)
{
* включение теневой грани(для обратной зависимости) в группу
it = inssh(ishg,array-header,…)
}... для каждого массива из списка dependent-array-list
* инициализация обновления теневых граней
it = strtsh(ishg)
* ожидание завершения обновления теневых граней
it = waitsh(ishg)
* уничтожение группы теневых граней
it = delobj(ishg)
. . .
* создание группы теневых граней
ishg = crtshg(0)
{
* включение теневой грани(для потоковой зависимости) в группу
it = insshd(ishg,array-header,…)
}... для каждого массива из списка dependent-array-list
* инициализация приема импортируемых элементов
it = recvsh(ishg)
* ожидание завершения операции обмена
it = waitsh(ishg)
ACROSS-block-2:
* инициализация передачи экспортируемых элементов
it = sendsh(ishg)
* ожидание завершения операции обмена
it = waitsh(ishg)
* уничтожение группы теневых граней
it = delobj(ishg)
Блок REMOTE-ACCESS-block генерируется в том случае, если в директиве PARALLEL есть спецификация REMOTE_ACCESS.
REMOTE-ACCESS-block:
В случае синхронной спецификации REMOTE_ACCESS :
{
* создание буферного массива
it = crtrbl(array-header,buffer-header,…)
* запуск загрузки буфера
it = loadrb(buffer-header,0)
* ожидание завершения загрузки буфера
it = waitrb(buffer-header)
* корректировка коэффициента CNB адресации элементов буфера,
* где NB – размерность буфера
buffer-header(NB+2) = buffer-header(NB+1)-
* buffer-header(NB)*buffer-header(NB+3) … -
* buffer-header(3)*buffer-header(2*NB+2)
}... для каждой удаленной ссылки
В случае асинхронной спецификации REMOTE_ACCESS (с именем группы RMG) :
IF (RMG(2) .EQ. 0) THEN
{
* создание буферного массива
it = crtrbl(array-header,buffer-header,…)
* корректировка коэффициента CNB адресации элементов буфера
buffer-header(NB+2) = buffer-header(NB+1)-
* buffer-header(NB)*buffer-header(NB+3) … -
* buffer-header(3)*buffer-header(2*NB+2)
* запуск загрузки буфера
it = loadrb(buffer-header,0)
* ожидание завершения загрузки буфера
it = waitrb(buffer-header)
* включение буфера в группу RMG
it = insrb(RMG(1),buffer-header)
}... для каждой удаленной ссылки
ELSE
IF (RMG(3) .EQ. 1) THEN
* ожидание завершения загрузки всех буферов группы RMG
it = waitbg(RMG(1))
RMG(3) = 0
ENDIF
ENDIF
4.3.2 Директивы PREFETCH и RESET
Директива
*DVM$ PREFETCH RMG
транслируется в следующую последовательность опреаторов:
IF (RMG(1) .EQ. 0) THEN
RMG(1) = crtbg(0,1)
RMG(2) = 0
ELSE
it = loadbg(RMG(1),1)
RMG(2) = 1
RMG(3) = 1
ENDIF
Директива
*DVM$ RESET RMG
заменяется оператором
it = delobj(RMG(1))
4.3.3 Директива MAP
Директива MAP задает отображение задачи на секцию массива процессоров. Директива
*DVM$ MAP TA(J) ONTO P(l1:u1,…,lr:ur)
заменяется операторами:
* создание подсистемы процессоров
TA(2,J) = crtps(P,l,u,0)
* отображение абстрактной машины на подсистему процессоров
it = mapam(TA(2,J),TA(1,J))
где:
l – вектор (lr
– 1, …, l1 – 1),
u – вектор (ur
– 1, …, u1 – 1).
4.3.4 Конструкция TASK_REGION
Конструкция TASK_REGION
*DVM$ TASK_REGION TA
*DVM$ ON TA(1)
block-1
*DVM$ END ON
. . .
*DVM$ ON TA(M)
block-M
*DVM$ END ON
*DVM$ END TASK_REGION
транслируется в
IF (runam(TA(2,1)).EQ.0) GO TO lab1
block-1
it = stopam()
lab1 CONTINUE
. . .
labM-1 IF (runam(TA(2,M)).EQ.0) GO TO labM
block-M
it = stopam()
labM CONTINUE
4.3.5 Конструкция параллельного цикла по задачам
Конструкция параллельного цикла по задачам
*DVM$ TASK_REGION TA
*DVM$ PARALLEL (I) ON TA(I)
DO label I = ...
тело-цикла
label CONTINUE
*DVM$ END TASK_REGION
транслируется в следующую последовательность операторов:
DO label I = ...
IF (runam(TA(2,I)).EQ.0) GO TO label
тело-цикла
it = stopam()
label CONTINUE
4.3.6 Другие директивы FDVM
Директива REDUCTION_START заменяется оператором:
* запуск выполнения редукций заданной группы
it = strtrd(reduction-group-var)
Директива REDUCTION_WAIT заменяется операторами:
* ожидание завершения выполнения редукций
it = waitrd(reduction-group-var)
* уничтожение редукционной группы
it = delobj(reduction-group-var)
Директива SHADOW_GROUP транслируется в следующий код:
* создание группы границ(теневых граней)
shadow-group-var = crtshg(...)
{
* включение теневой грани в группу
it = inssh(shadow-group-var,array-header,...)
}... для каждого массива в списке renewee-list
Директива SHADOW_START заменяется оператором:
* инициализация обновления теневых граней
it = strtsh(shadow-group-var)
Директива SHADOW_WAIT заменяется оператором:
* ожидание завершения обновления теневых граней
it = waitsh(shadow-group-var)
Директива NEW_VALUE оказывает влияние на трансляцию следующей за ней директивы (REDISTRIBUTE или REALIGN) и не влечет за собой генерацию новых операторов. Директивы REDISTRIBUTE и REALIGN реализуются функциями redis( ) и realn( ), соответственно. Флаг NewSign устанавливается равным 1 для переменных, указанных в директиве NEW_VALUE.
4.3.7 Директивы отладки
Операторы отладки DEBUG и ENDDEBUG не являются исполняемыми операторами и не требуют генерации новых операторов. Они определяют фрагмент программы, о котором пользователь хочет получить информацию в процессе отладки. Эти директивы вызывают переустановку режима компиляции. Режим компиляции зависит от максимально допустимого уровня отладки заданного в директиве DEBUG и уровня отладки, указанного для данного фрагмента в командной строке (опции – d и -e).
Директива отладки TRACE ON (TRACE OFF) “включает” (“выключает”) сбор трассы выполнения программы, реализуется с помощью функции tron( )(troff( )) системы поддержки Lib-DVM.
Если пользователь задал с помощью опции –d отладочный режим компиляции, тогда в начале и в конце каждого цикла (параллельного и последовательного) компилятор вставляет обращения к функциям отладчика: dbegpl( ), dbegsl( ) и dendl( ). Кроме того, компилятор должен обеспечить трассирование обращений к данным, выполнения итераций и задач. Обращения к соответствующим функциям отладчика включаются в программу.
Директивы INTERVAL и END INTERVAL предназначены для объявления интервалов выполнения программы, на которых пользователь собирается получить характеристики эффективности. Компилятор вставляет в программу обращения к анализатору производительности в начале и в конце каждого интервала:
call binter(...)
. . .
call einter(...)
Если пользователь задал с помощью опции –e режим анализа производительности, тогда в начале и в конце каждого цикла (параллельного и последовательного) компилятор вставляет обращения к функциям анализатора производительности: bploop( ), bsloop( ), и eloop( ).
4.3.8 Операторы ввода-вывода
Операторы ввода-вывода, осуществляющие передачу данных, управление и другие вспомогательные операции с внешним файлом, выполняются на одном процессоре (процессоре ввода-вывода), специально выделяемом для этой цели системой поддержки выполнения FDVM программы. Операция ввода-вывода значения размноженной переменной производится над копией переменной, размещенной на процессоре ввода-вывода. Введенное значение рассылается остальным процессорам. Ввод-вывод распределенного массива реализуется с помощью буфера, размещенного на процессоре ввода-вывода. При вводе данные из внешнего файла передаются в буфер, а затем рассылаются тем процессорам, на которые распределен массив. Когда распределенный массив выводится, данные с процессоров, где локализованы элементы массива, сначала пересылаются в буфер, а из буфера передаются во внешний файл.
Компилятор заменяет любой оператор ввода-вывода оператором логический IF:
IF(tstio().NE.0 ) оператор-вввода-вывода
за исключением операторов ввода-вывода во внутренний файл, которые остаются без изменения. Функция tstio( ) возвращает значение 1, если текущий процессор является процессором ввода-вывода.
Для оператора READ, а также любого оператора с управляющим параметром IOSTAT компилятор генерирует обращение к функции srmem( ) для рассылки данных с процессора ввода-вывода на другие процессоры.
При вводе-выводе распределенного массива в программе пользователя выделяется память для буфера ввода-вывода.
Пусть A(N1,N2,...,Nk) – ссылка на распределенный массив размерности k, BUF(L) – вектор того же типа, что и массив A. Тогда компилятор заменит оператор ввода-вывода последовательностью операторов по следующей схеме:
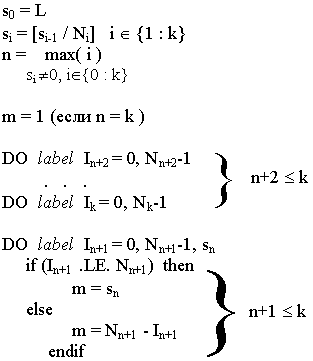
ввод:
| IF(tstio( ) .ne. 0 ) READ (...) (BUF(j), j = 1, N1 * ...*Nn * m) | |
| n >= 1 | |
| копирование-секции-массива (BUF(1 : N1 * ...*Nn * m), | |
| n >= 1 | |
| A(1: N1,...,1:Nn , In+1 +1: In+1 +m , In+2 +1, ..., Ik +1) ) | |||||||
| n >= 1 | n+1 <= k | n+2 <= k | |||||
вывод:
| копирование-секции-массива (BUF(1 : N1 * ...*Nn * m), | |
| n >= 1 | |
| A(1: N1,...,1:Nn , In+1 +1: In+1 +m , In+2 +1, ..., Ik +1) ) | |||||||
| n >= 1 | n+1 <= k | n+2 <= k | |||||
| IF(tstio( ) .ne. 0 ) WRITE (...) (BUF(j), j = 1, N1 * ...*Nn * m) | |
| n >= 1 | |
label CONTINUE
Операция копирования-секции-массива реализуется с помощью функции системы поддержки arrcpy( ).
5 Трансляция HPF-DVM программы
5.1 Оператор присваивания и другие исполняемые операторы вне цикла INDEPENDENT
HPF-DVM программа выполняется по правилу собственных вычислений. Оператор присваивания
A(I1,I2, ..., IN) = f (B(J1,J2, ..., JK),…)
который встречается вне цикла INDEPENDENT, заменяется на
* копирование элемента распределенного массива
it = rwelmf(B-header,buffer-var,index-array)
. . .
* запрос о том, является ли A(I1,I2, ..., IN) элементом локальной секции
IF(tstelm(A-header,index-array) .NE. 0)
* DVM-reference-A = f(buffer-var,…)
Каждая ссылка на распределенный массив в правой части оператора присваивания, в операторе CALL или в любом другом исполняемом операторе заменяется ссылкой на буферную переменную и для нее генерируется следующий оператор:
* копирование элемента распределенного массива
it = rwelmf(array-header,buffer-var,index-array)
Тесно-гнездовой цикл INDEPENDENT:
*HPF$ INDEPENDENT
DO label I1 = ...
. . .
*HPF$ INDEPENDENT
DO label In = ...
тело-цикла
label CONTINUE
транслируется в:
* создание параллельного цикла
ipl = crtpl(n)
* отображение параллельного цикла
it = mappl(ipl,...)
[ inquiry-block ]
* запрос о продолжении выполнения параллельного цикла
lab1 if(dopl(ipl) .eq. 0) go to lab2
DO label I1 = ...
. . .
DO label In = ...
тело-цикла
label CONTINUE
go to lab1
* завершение параллельного цикла
lab2 it = endpl(ipl)
Блок операторов inquiry-block генерируется только в том случае, если в теле цикла в правых частях операторов присваивания встретились ссылки на распределенные массивы.
ishg = 0
ibg = 0
{
* запрос о типе доступа к удаленному элементу распределенного массива
kind = rmkind(array-header,buffer-header,…,
* low-shadow-array,high-shadow-array)
IF (kind .EQ. 4) THEN
IF (ishg .EQ. 0) THEN
* создание группы буферов удаленных элементов
ibg = crtbg(0,1)
ENDIF
* включение буфера удаленных элементов в группу
it = insrb(ibg, buffer-header)
* вычисление коэффициентов адресации элементов массива
* NB is rank of buffer array
header-copy(1) = buffer-header(2)
. . .
header-copy(NB-1) = buffer-header(NB)
header-copy(NB) = 1
header-copy(NB+1) = buffer-header(NB+1)-
* buffer-header(NB)*buffer-header(NB+3) … -
* buffer-header(3)*buffer-header(2*NB+2)
ELSE
IF (kind .NE. 1) THEN
IF (ishg .EQ. 0) THEN
* создание группы теневых граней
ishg = crtshg(0)
ENDIF
* включение теневой грани в группу
* (с угловыми элементами или без)
IF (kind .EQ. 2) THEN
it = inssh(ishg,array-header,low-shadow-array,
* high-shadow-array,0)
ELSE
it = inssh(ishg,array-header,low-shadow-array,
* high-shadow-array,1)
ENDIF
* вычисление коэффициентов адресации элементов массива
header-copy(1) = f1(array-header,IkN)
. . .
header-copy(NB) = f1(array-header,Ik1)
header-copy(NB+1) = f2(buffer-header(2:N+1),I1,…,IN)
ENDIF
}... для каждой ссылки на распределенный массив
* обновление теневых граней, включенных в группу ishg
IF (ishg .NE. 0) THEN
it = strtsh(ishg)
it = waitsh(ishg)
ENDIF
* загрузка буферов удаленных элементов группы ibg
IF (ibg .NE. 0) THEN
it = loadbg(ibg,1)
it = waitbg(ibg)
ENDIF