РАЗРАБОТКА ПАРАЛЛЕЛЬНЫХ
ПРОГРАММ ДЛЯ ВЫЧИСЛИТЕЛЬНЫХ КЛАСТЕРОВ
И СЕТЕЙ.
Проблемы
и перспективы[1].
В.А. Крюков
Институт
прикладной математики им. М.В. Келдыша РАН
e-mail: krukov@keldysh.ru
Аннотация.
В
работе делается сравнительный анализ пяти
разных подходов к разработке параллельных
программ (MPI, HPF, OpenMP, OpenMP+MPI и DVM) со следующих
позиций: легкость программирования,
эффективность разработанных программ,
переносимость и повторное использование
программ, качество средств отладки
программ.
1. Введение
Последние годы во всем мире происходит бурное внедрение вычислительных кластеров. Это вызвано тем, что кластеры стали общедоступными и дешевыми аппаратными платформами для высокопроизводительных вычислений. Одновременно резко возрос интерес к проблематике вычислительных сетей (GRID) и широко распространяется понимание того, что внедрение таких сетей будет иметь громадное влияние на развитие человеческого общества, сравнимое с влиянием на него появления в начале века единых электрических сетей [1]. Поэтому, рассматривая проблемы освоения кластеров необходимо принимать во внимание и то, что они являются первой ступенькой в создании таких вычислительных сетей.
Поскольку единого определения вычислительного кластера не существует, для упрощения дальнейшего изложения введем некоторую классификацию, которая будет отражать свойства программно-аппаратной платформы, существенные с точки зрения разработки прикладных параллельных программ.
Вычислительный кластер – это мультикомпьютер, состоящий из множества отдельных компьютеров (узлов), связанных между собой единой коммуникационной системой. Каждый узел имеет свою локальную оперативную память. При этом общей физической оперативной памяти для узлов не существует. Каждый узел может быть мультипроцессором (мультипроцессорный компьютер с общей памятью). Коммуникационная система обычно позволяет узлам взаимодействовать между собой только посредством передачи сообщений, но некоторые системы могут обеспечивать и односторонние коммуникации - позволять любому узлу выполнять массовый обмен информацией между своей памятью и локальной памятью любого другого узла.
Если на вычислительном кластере аппаратно или программно-аппаратно реализована DSM (distributed shared memory - распределенная общая память), позволяющая выполняющимся на разных узлах программам (любым, даже ассемблерным) взаимодействовать через общие переменные, то такой кластер будем называть DSM-кластер. Если такая DSM отсутствует, и прикладные программы взаимодействуют посредством передачи сообщений, то вычислительный кластер будем называть DM-кластер (DM - distributed memory).
Если все входящие в состав вычислительного кластера узлы имеют одну и ту же архитектуру и производительность, то мы имеем дело с однородным вычислительным кластером. Иначе – с неоднородным.
С точки зрения разработки прикладных параллельных программ нет каких-либо принципиальных различий между однородным DM-кластером и MPP (МВС-100, МВС-1000, IBM SP-2) или однородным DSM-кластером и SPP (Convex Exemplar, HP 9000 V-class, SGI Origin 2000). Различие, в основном, заключается в большей доступности и меньшей стоимости кластеров по сравнению с мультипроцессорными ЭВМ с распределенной памятью, в которых используются специальные коммуникационные системы и специализированные узлы.
В настоящее время, когда говорят о кластерах, то часто подразумевают однородность. Однако, для того, чтобы сохранить высокий уровень соотношения производительность/стоимость приходится при наращивании кластера использовать наиболее подходящие в данный момент процессоры, которые могут отличаться не только по производительности, но и по архитектуре. Поэтому постепенно большинство кластеров могут стать неоднородными кластерами.
Неоднородность же вносит следующие серьезные проблемы.
Различие в производительности процессоров требует соответствующего учета при распределении работы между процессами, выполняющимися на разных процессорах.
Различие в архитектуре процессоров требует подготовки разных выполняемых файлов для разных узлов, а в случае различий в представлении данных может потребоваться и преобразование информации при передаче сообщений между узлами (не говоря уже о трудностях использования двоичных файлов). Если существуют различия в представлении данных, то построение неоднородного DSM-кластера представляется просто невозможной.
Тем не менее, любой кластер можно рассматривать как единую аппаратно-программную систему, имеющую единую коммуникационную систему, единый центр управления и планирования загрузки.
Вычислительные сети (GRID) будут объединять ресурсы множества кластеров, многопроцессорных и однопроцессорных ЭВМ, принадлежащих разным организациям и подчиняющихся разным дисциплинам использования. Разработка параллельных программ для них усложняется из-за следующих проблем.
Конфигурация выделяемых ресурсов (количество узлов, их архитектура и производительность) определяется только в момент обработки заказа на выполнение вычислений. Поэтому программист не имеет возможностей для ручной настройки программы на эту конфигурацию. Желательно осуществлять настройку программы на выделенную конфигурацию ресурсов динамически, без перекомпиляции.
К изначальной неоднородности коммуникационной среды добавляется изменчивость ее характеристик, вызываемая изменениями загрузки сети. Учет такой неоднородности коммуникаций является очень сложной задачей.
Все это требует гораздо более высокого уровня автоматизации разработки параллельных программ, чем тот, который доступен в настоящее время прикладным программистам.
С 1992 года, когда мультикомпьютеры стали самыми производительными вычислительными системами, резко возрос интерес к проблеме разработки для них параллельных прикладных программ. К этому моменту уже было ясно, что трудоемкость разработки прикладных программ для многопроцессорных систем с распределенной памятью является главным препятствием для их широкого внедрения. За прошедший с тех пор период предложено много различных подходов к разработке параллельных программ, созданы десятки различных языков параллельного программирования и множество различных инструментальных средств. Среди них можно отметить следующие интересные отечественные разработки – Норма [2], Фортран-GNS [3], Фортран-DVM [4], mpC [5], Т-система [6].
Целью данной работы является сравнительный анализ пяти различных подходов к разработке параллельных программ для вычислительных кластеров и сетей – MPI[7,8], HPF[9,10], OpenMP[11], OpenMP+MPI и DVM[4,12]. Выбор для анализа именно этих подходов объясняется следующими соображениями:
· Все эти подходы ориентированы на программистов, использующих стандартные языки Фортран или Си. Именно эти программисты и разрабатывают, в основном, параллельные вычислительные программы.
· В основе этих подходов лежат существенно различающиеся модели и языки параллельного программирования.
· На базе этих подходов созданы инструментальные средства разработки параллельных программ, доступные на многих аппаратных платформах.
· И, наконец, для всех этих подходов имеется информация об эффективности выполнения соответствующих реализаций тестов NPB 2.3 [13], что позволяет объективно судить о пригодности этих подходов для разработки сложных параллельных программ.
Предпочтительность использования того или иного подхода определяют следующие факторы:
· Легкость программирования;
· Эффективность разработанных программ;
· Переносимость и повторное использование программ;
· Качество средств отладки программ (функциональной отладки и отладки эффективности).
Именно с этих позиций анализируются указанные подходы в данной работе.
2. Модели и языки параллельного программирования
Как было сказано выше, имеются две
основные модели параллельного выполнения
программы на кластере – модель передачи
сообщений и модель общей памяти.
В первой модели параллельная программа представляет собой систему процессов, взаимодействующих посредством передачи сообщений. Эта модель может быть использована на любых кластерах.
Во второй модели параллельная программа представляет собой систему нитей, взаимодействующих посредством общих переменных и примитивов синхронизации. Нить (по-английски ”thread”) – это легковесный процесс, имеющий с другими нитями общие ресурсы, включая общую оперативную память. Вторая модель доступна для использования только на DSM-кластерах.
Можно выбрать в качестве модели программирования одну из этих моделей выполнения. При этом возможны три способа построения языка программирования:
· Расширение стандартного языка последовательного программирования библиотечными функциями (например, Фортран+MPI, Си+Pthreads);
· Расширение стандартного языка последовательного программирования специальными конструкциями (например, Фортран-GNS, Си-GNS);
· Разработка нового языка (например, Occam).
Однако обе основные модели выполнения являются довольно низкоуровневыми. Поэтому главным недостатком выбора одной из них в качестве модели программирования является то, что такая модель непривычна и неудобна для программистов, разрабатывающих вычислительные программы. Она заставляет его иметь дело с параллельными процессами и низкоуровневыми примитивами передачи сообщений или синхронизации. Особенно большие трудности возникают при необходимости использования многоуровневого параллелизма (например, параллелизм между разными подзадачами и параллелизм внутри этих подзадач).
Кроме того, программист обычно вынужден иметь и сопровождать два варианта программы – последовательный и параллельный.
Поэтому вполне естественно, что прикладной программист хотел бы получить инструмент, автоматически преобразующий его последовательную программу в параллельную программу для кластера. К сожалению, такое автоматическое распараллеливание невозможно в силу следующих причин.
Во-первых, поскольку взаимодействие процессоров через коммуникационную систему требует значительного времени (латентность – время самого простого взаимодействия - велика по сравнению со временем выполнения одной машинной команды), то вычислительная работа должна распределяться между процессорами крупными порциями.
Совсем другая ситуация была на векторных машинах и на мультипроцессорах, где автоматическое распараллеливание программ на языке Фортран реально использовалось и давало хорошие результаты. Для автоматического распараллеливания на векторных машинах (векторизации) достаточно было проанализировать на предмет возможности параллельного выполнения (замены на векторные операции) только самые внутренние циклы программы. В случае мультипроцессоров приходилось уже анализировать объемлющие циклы для нахождения более крупных порций работы, распределяемых между процессорами.
Укрупнение распределяемых порций работы требует анализа более крупных фрагментов программы, обычно включающих в себя вызовы различных процедур. Это, в свою очередь, требует сложного межпроцедурного анализа. Поскольку в реальных программах на языке Фортран могут использоваться конструкции, статический анализ которых принципиально невозможен (например, косвенная индексация элементов массивов), то с увеличением порций распределяемой работы увеличивается вероятность того, что распараллеливатель откажется распараллеливать те конструкции, которые на самом деле допускают параллельное выполнение.
Во-вторых, в отличие от многопроцессорных ЭВМ с общей памятью, на системах с распределенной памятью необходимо произвести не только распределение вычислений, но и распределение данных, а также обеспечить на каждом процессоре доступ к удаленным данным - данным, расположенным на других процессорах. Для обеспечения эффективного доступа к удаленным данным требуется производить анализ индексных выражений не только внутри одного цикла, но и между разными циклами. К тому же, недостаточно просто обнаруживать факт наличия зависимости по данным, а требуется определить точно тот сегмент данных, который должен быть переслан с одного процессора на другой.
В третьих, распределение вычислений и данных должно быть произведено согласованно.
Несогласованность распределения вычислений и данных приведет, вероятнее всего, к тому, что параллельная программа будет выполняться гораздо медленнее последовательной. Если на системе с общей памятью распараллелить один цикл, занимающий 90 процентов времени решения задачи, то можно рассчитывать на почти десятикратное ускорение программы (даже если оставшиеся 10 процентов будут выполняться последовательно). На системе с распределенной памятью распараллеливание этого цикла без учета последовательной части может вызвать не ускорение, а замедление программы. Последовательная часть будет выполняться на одном процессоре или на всех процессорах. Если в этой части используются распределенные массивы, то для такого выполнения потребуется интенсивный обмен данными между процессорами.
Согласованное распределение вычислений и данных требует тщательного анализа всей программы, и любая неточность анализа может привести к катастрофическому замедлению выполнения программы.
Невозможность полностью автоматического распараллеливания имеющихся последовательных программ для их выполнения на кластерах, не означает, конечно, неактуальности работ в этом направлении. Если ввести некоторую дисциплину при написании программ, и, возможно, позволить вставлять в программу некоторые подсказки распараллеливателю, то такие программы могут автоматически преобразовываться в программы, способные выполняться параллельно на кластере. Однако в этом случае следует говорить скорее не о распараллеливании последовательных программ, а о написании новых параллельных программ на традиционных языках последовательного программирования или их расширениях.
Теперь переходим к рассмотрению подходов, выбранных для сравнительного анализа.
2.1. Модель
передачи сообщений. MPI.
В модели передачи сообщений параллельная программа представляет собой множество процессов, каждый из которых имеет собственное локальное адресное пространство. Взаимодействие процессов - обмен данными и синхронизация - осуществляется посредством передачи сообщений. Обобщение и стандартизация различных библиотек передачи сообщений привели в 1993 году к разработке стандарта MPI (Message Passing Interface). Его широкое внедрение в последующие годы обеспечило коренной перелом в решении проблемы переносимости параллельных программ, разрабатываемых в рамках разных подходов, использующих модель передачи сообщений в качестве модели выполнения.
В числе основных достоинств MPI по сравнению с интерфейсами других коммуникационных библиотек обычно называют следующие его возможности:
· Возможность использования в языках Фортран, Си, Си++;
· Предоставление возможностей для совмещения обменов сообщениями и вычислений;
· Предоставление режимов передачи сообщений, позволяющих избежать излишнего копирования информации для буферизации;
· Широкий набор коллективных операций (например, широковещательная рассылка информации, сбор информации с разных процессоров), допускающих гораздо более эффективную реализацию, чем использование соответствующей последовательности пересылок точка-точка;
· Широкий набор редукционных операций (например, суммирование расположенных на разных процессорах данных, или нахождение их максимальных или минимальных значений), не только упрощающих работу программиста, но и допускающих гораздо более эффективную реализацию, чем это может сделать прикладной программист, не имеющий информации о характеристиках коммуникационной системы;
· Удобные средства именования адресатов сообщений, упрощающие разработку стандартных программ или разделение программы на функциональные блоки;
· Возможность задания типа передаваемой информации, что позволяет обеспечить ее автоматическое преобразование в случае различий в представлении данных на разных узлах системы.
Однако разработчики MPI подвергаются и суровой критике за то, что интерфейс получился слишком громоздким и сложным для прикладного программиста. Интерфейс оказался сложным и для реализации, в итоге, в настоящее время практически не существует реализаций MPI, в которых в полной мере обеспечивается совмещение обменов с вычислениями.
Появившийся в 1997 проект стандарта MPI-2 [8] выглядит еще более громоздким и неподъемным для полной реализации. Он предусматривает развитие в следующих направлениях:
· Динамическое создание и уничтожение процессов;
· Односторонние коммуникации и средства синхронизации для организации взаимодействия процессов через общую память (для эффективной работы на системах с непосредственным доступом процессоров к памяти других процессоров);
· Параллельные операции ввода-вывода (для эффективного использования существующих возможностей параллельного доступа многих процессоров к различным дисковым устройствам).
2.2. Модель параллелизма по данным. HPF.
В модели параллелизма по данным отсутствует понятие процесса и, как следствие, явная передача сообщений или явная синхронизация. В этой модели данные последовательной программы распределяются программистом по процессорам параллельной машины. Последовательная программа преобразуется компилятором в параллельную программу, выполняющуюся либо в модели передачи сообщений, либо в модели с общей памятью. При этом вычисления распределяются по правилу собственных вычислений: каждый процессор выполняет только вычисления собственных данных, т.е. данных, распределенных на этот процессор.
Модель параллелизма по данным имеет следующие достоинства.
· Параллелизм по данным является естественным параллелизмом вычислительных задач, поскольку для них характерно вычисление по одним и тем же формулам множества однотипных величин – элементов массивов.
· В модели параллелизма по данным сохраняется последовательный стиль программирования. Программист не должен представлять программу в виде взаимодействующих процессов и заниматься низкоуровневым программированием передач сообщений и синхронизации.
· Распределение вычисляемых данных между процессорами – это не только самый компактный способ задать распределение работы между процессорами, но и способ повышения локализации данных. Чем меньше данных требуется процессору для выполнения возложенной на него работы, тем быстрее она будет выполнена (лучше используется кэш-память, меньше подкачек с диска страниц виртуальной памяти, меньше пересылок данных с других процессоров).
Обобщение и стандартизация моделей параллелизма по данным привели к созданию в 1993 году стандарта HPF (High Performance Fortran) - расширения языка Фортран 90. Аналогичные расширения были предложены для языка Си и Си++.
Краткий обзор возможностей HPF.
Как уже было сказано выше, прежде всего программист должен распределить данные между процессорами. Это распределение производится в два этапа. Сначала с помощью директивы ALIGN задается соответствие между взаимным расположением элементов нескольких массивов, а затем вся эта группа массивов с помощью директивы DISTRIBUTE отображается на решетку процессоров. Это отображение, например, может осуществляться следующим образом: каждый массив разрезается несколькими гиперплоскостями на секции примерно одинакового объема, каждая из которых будет расположена на своем процессоре. Заданное распределение данных может быть изменено на этапе выполнения программы с помощью операторов REALIGN и REDISTRIBUTE.
В HPF реализуется параллелизм следующих конструкций языка Фортран 90/95: операции над секциями массивов, DO циклы, оператор и конструкция FORALL.
Операции над секциями массивов выполняются параллельно в соответствии с распределением данных. Если для их выполнения требуются коммуникации, то они обеспечиваются компилятором.
Оператор и конструкция FORALL могут рассматриваться как обобщение и расширение операций над секциями массивов.
Многие встроенные функции имеют дело с массивами (например, редукционные функции) и могут выполняться параллельно.
Безусловно, по сравнению с MPI язык HPF намного упрощает написание параллельных программ, однако его реализация требует от компилятора очень высокого интеллекта. Конечно, самая сложная часть работы, которая вызывала проблемы при автоматическом распараллеливании – распределение данных – возлагается теперь на программиста. Но, и с оставшейся частью работы компилятор не всегда способен справиться без дополнительных подсказок программиста. Некоторые такие подсказки были включены в HPF, но все равно оставались серьезные сомнения относительно эффективности HPF-программ.
К сожалению, эти сомнения оказались не напрасными. В течение нескольких лет не удалось создать компилятора с приемлемой эффективностью. В 1997 году появился проект стандарта HPF2 [10] , в котором существенно расширены возможности программиста по спецификации тех свойств его программы, извлечь которые на этапе компиляции очень трудно или даже вообще невозможно.
2.3. Модель
параллелизма по управлению. OpenMP.
Эта модель возникла уже давно как естественная альтернатива явному использованию модели общей памяти при разработке программ для мультипроцессоров. Вместо программирования в терминах нитей предлагалось расширить языки специальными управляющими конструкциями – параллельными циклами и параллельными секциями. Создание и уничтожение нитей, распределение между ними витков параллельных циклов или параллельных секций (например, вызовов процедур) – все это брал на себя компилятор. Первая попытка стандартизовать такую модель привела к появлению в 1990 году проекта языка PCF Fortran (проект стандарта X3H5). Однако, этот проект [14] тогда не привлек широкого внимания и, фактически, остался только на бумаге. Возможно, что причиной этого было снижение интереса к мультипроцессорам и всеобщее увлечение мультикомпьютерами и HPF.
Однако, спустя несколько лет ситуация сильно изменилась. Во-первых, успехи в развитии элементной базы сделали очень перспективным и экономически выгодным создавать мультипроцессоры. Во-вторых, надежды на то, что HPF станет фактическим стандартом для разработки вычислительных программ, не оправдались.
Крупнейшие производители компьютеров и програмного обеспечения объединили свои усилия и в октябре 1997 года выпустили описание языка OpenMP Fortran – расширение языка Фортран 77. Позже вышли аналогичные расширения языков Си и Фортран 90/95.
Краткий обзор возможностей OpenMP.
OpenMP – это интерфейс прикладной программы, расширяющий последовательный язык программирования набором директив компилятора, вызовов функций библиотеки поддержки выполнения и переменных среды.
Программа начинает свое выполнение как один процесс, называемый главной нитью. Главная нить выполняется последовательно, пока не встретится первая параллельная область программы. Параллельная область определяется парой директив PARALLEL и END PARALLEL. При входе в параллельную область главная нить порождает некоторое число подчиненных ей нитей, которые вместе с ней образуют текущую группу нитей. Все операторы программы, находящиеся в параллельной конструкции, включая и вызываемые изнутри нее процедуры, выполняются всеми нитями текущей группы параллельно, пока не произойдет выход из параллельной области или встретится одна из конструкций распределения работы - DO, SECTIONS или SINGLE.
Конструкция DO служит для распределения витков цикла между нитями, конструкция SECTIONS – для распределения между нитями указанных секций программы, а конструкция SINGLE указывает секцию, которая должна быть выполнена только одной нитью.
При выходе из параллельной конструкции все порожденные на входе в нее нити сливаются с главной нитью, которая и продолжает дальнейшее выполнение.
В программе может быть произвольное число параллельных областей, причем допускается их вложенность.
При параллельной области можно указать классы используемых в ней переменных (общие или приватные).
Имеются директивы высокоуровневой синхронизации (критические секции, барьер, и пр.).
Набор функций системы поддержки и переменных окружения служит для управления количеством создаваемых нитей, способами распределения между ними витков циклов, для низкоуровневой синхронизации нитей с помощью замков.
Все операторы, входящие лексически в параллельную конструкцию, определяют ее статическое содержимое (экстент). В динамическое содержимое параллельной конструкции входят и все вызываемые из нее процедуры.
Программист может использовать директивы в процедурах, вызываемых из параллельной конструкции. Такие директивы, которые не входят в статическое содержимое параллельной конструкции, но принадлежат ее динамическому содержимому, называются нелокализованными директивами. Программист может, внеся небольшие изменения в последовательную программу (охватив параллельной конструкцией только верхние уровни дерева вызовов процедур), обеспечить параллельное выполнение почти всей программы и управлять этим выполнением, вставляя директивы в вызываемые процедуры.
Интересно, что подход OpenMP является диаметрально противоположным к подходу HPF:
· Вместо параллелизма по данным – параллелизм по управлению;
· Вместо изощренного статического анализа и автоматического нахождения операторов, способных выполняться параллельно – явное и полное задание параллелизма программистом;
· Вместо языка, требующего специального HPF-компилятора даже для работы на последовательной ЭВМ – язык, позволяющий на последовательной ЭВМ компилироваться и выполняться в среде Фортран 77.
Недостатком OpenMP, помимо ограниченности его области применения (мультипроцессоры и DSM-кластеры) является то, что имеющиеся в нем средства распараллеливания циклов с зависимостями по данным являются слишком низкоуровневыми. В проекте PCF Fortran для этой цели предлагались средства более высокого уровня. Кроме того, программисту фактически позволяется использовать напрямую модель выполнения (программировать в терминах нитей), что может провоцировать создание плохо переносимых программ.
2.4.
Гибридная модель параллелизма по
управлению с передачей сообщений. OpenMP+MPI.
Успешное внедрение OpenMP на мультипроцессорах и DSM-мультикомпьютерах резко активизировало исследования, направленные на поиски путей распространения OpenMP на DM-мультикомпьютеры и сети ЭВМ. Эти исследования сосредоточились, в основном, на двух направлениях:
· Расширение языка средствами описания распределения данных;
· Программная реализация системы DSM, использующей дополнительные указания компилятора, вставляемые им в выполняемую программу.
Однако ожидать в ближайшее время практического результата от этих исследований очень трудно.
Зато нет никаких препятствий для использования гибридного подхода, когда программа представляет собой систему взаимодействующих MPI-процессов, а каждый процесс программируется на OpenMP.
Преимущества такого смешанного подхода с точки зрения упрощения программирования очевидны в том случае, когда в программе есть два уровня параллелизма – параллелизм между подзадачами и параллелизм внутри подзадачи. Такая ситуация возникает, например, при использовании многообластных (многоблочных) методов решения вычислительных задач. Программировать на MPI сами подзадачи гораздо сложнее, чем их взаимодействие, поскольку распараллеливание подзадачи связано с распределением элементов массивов и витков циклов между процессами. Организация же взаимодействия подзадач таких сложностей не вызывает, поскольку сводится к обмену между ними граничными значениями. Нечто подобное программисты делали раньше на однопроцессорных ЭВМ, когда для экономии памяти на каждом временном шаге выполняли подзадачи последовательно друг за другом.
Широкое распространение кластеров, имеющих в качестве узлов мультипроцессоры, также подталкивает к использованию гибридного подхода, поскольку использование OpenMP на мультипроцессоре может для некоторых задач (например, вычислений на неструктурных сетках) дать заметный выигрыш в эффективности.
Основной недостаток этого подхода также очевиден - программисту надо знать и уметь использовать две разные модели параллелизма и разные инструментальные средства.
2.5. Модель
параллелизма по данным и управлению. DVM.
Эта модель, положенная в основу языков параллельного программирования Фортран-DVM и Си-DVM, объединяет достоинства модели параллелизма по данным и модели параллелизма по управлению. Базирующаяся на этих языках система разработки параллельных программ (DVM) создана в Институте прикладной математики им. М.В. Келдыша РАН.
В отличие от модели параллелизма по данным, в системе DVM программист распределяет по процессорам виртуальной параллельной машины не только данные, но и соответствующие вычисления. При этом на него возлагается ответственность за соблюдение правила собственных вычислений. Кроме того, программист определяет общие данные, т.е. данные, вычисляемые на одних процессорах и используемые на других процессорах. И, наконец, он отмечает точки в последовательной программе, где происходит обновление значений общих данных.
При построении системы DVM был использован новый подход, который характеризуется следующими принципами.
1. Система должна базироваться на высокоуровневой модели выполнения параллельной программы, удобной и понятной для программиста, привыкшего программировать на последовательных языках. Такая модель (DVM-модель) была разработана в 1994 году [1].
2. Языки параллельного программирования должны представлять собой стандартные языки последовательного программирования, расширенные спецификациями параллелизма. Эти языки должны предлагать программисту модель программирования, достаточно близкую к модели выполнения. Знание программистом модели выполнения его программы и ее близость к модели программирования существенно упрощает для него анализ производительности программы и проведение ее модификаций, направленных на достижение приемлемой эффективности.
3. Спецификации параллелизма должны быть прозрачными для обычных компиляторов (например, оформляться в виде специальных комментариев). Во-первых, это упрощает внедрение новых параллельных языков, поскольку программист знает, что его программа без каких-либо изменений может выполняться в последовательном режиме на любых ЭВМ. Во-вторых, это позволяет использовать следующий метод поэтапной отладки DVM-программ. На первом этапе программа отлаживается на рабочей станции как последовательная программа, используя обычные методы и средства отладки. На втором этапе программа выполняется на той же рабочей станции в специальном режиме проверки DVM-указаний. На третьем этапе программа может быть выполнена в специальном режиме, когда промежуточные результаты параллельного выполнения сравниваются с эталонными результатами (например, результатами последовательного выполнения).
4. Основная работа по реализации модели выполнения параллельной программы (например, распределение данных и вычислений) должна осуществляться динамически специальной системой - системой поддержки выполнения DVM-программ. Это позволяет обеспечить динамическую настройку DVM-программ при запуске (без перекомпиляции) на параметры приложения (количество и размер массивов данных) и конфигурацию параллельного компьютера (количество процессоров и их производительность). Тем самым программист получает возможность иметь один вариант программы для выполнения на последовательных ЭВМ и параллельных ЭВМ различной конфигурации. Кроме того, на основании информации о выполнении DVM-программы на однопроцессорной ЭВМ можно посредством моделирования работы системы поддержки предсказать характеристики выполнения этой программы на параллельной ЭВМ с заданными параметрами (производительностью процессоров и коммуникационных каналов).
Большое влияние на разработку этого подхода оказали работы по языку Fortran D [15], по языку PCF Fortran, а также участие авторов в создании управляемой виртуальной памяти для ЭВМ БЭСМ-6 [16].
Краткий обзор возможностей языков Фортран-DVM и Си-DVM.
Программа
на языках Фортран-DVM и Си-DVM, помимо описания
алгоритма обычными средствами языков
Фортран 77 или Си, содержит правила
параллельного выполнения этого алгоритма.
Программисту
предоставляются следующие возможности
спецификации параллельного выполнения
программы:
·
распределение элементов массива между
процессорами;
·
распределение витков цикла между
процессорами;
·
спецификация параллельно
выполняющихся секций программы (параллельных
задач) и отображение их на процессоры;
·
организация эффективного доступа к
удаленным (расположенным на других
процессорах) данным;
·
организация эффективного выполнения
редукционных операций - глобальных
операций с расположенными на различных
процессорах данными (таких, как их
суммирование или нахождение их
максимального или минимального значения).
Модель выполнения программы можно упрощенно описать следующим образом.
Параллельная программа на исходном языке Фортран-DVM (или Си-DVM) превращается в программу на языке Фортран 77 (или Си), содержащую вызовы функций системы поддержки, и выполняющуюся в соответствии с моделью SPMD (одна программа – много данных) на каждом выделенном задаче процессоре.
В момент запуска программы существует единственная её ветвь (поток управления), которая начинает свое выполнение с первого оператора программы сразу на всех процессорах многопроцессорной системы.
Многопроцессорной системой (или системой процессоров) называется та машина, которая предоставляется программе пользователя аппаратурой и базовым системным программным обеспечением. Для распределённой ЭВМ примером такой машины может служить MPI-машина. В этом случае, многопроцессорная система - это группа MPI-процессов, которые создаются при запуске параллельной программы на выполнение. Число процессоров многопроцессорной системы и её представление в виде многомерной решетки задаётся в командной строке при запуске программы.
Все объявленные в программе переменные (за исключением специально указанных "распределённых" массивов) размножаются по всем процессорам.
При входе в параллельную конструкцию (параллельный цикл или область параллельных задач) ветвь разбивается на некоторое количество параллельных ветвей, каждая из которых выполняется на выделенном ей процессоре многопроцессорной системы.
При
выходе из параллельной конструкции все
ветви сливаются в ту же самую ветвь,
которая выполнялась до входа в
параллельную конструкцию.
Недостатком системы DVM является то, что предоставляются только параллельные расширения языков Фортран 77 и Си, а расширения языков Фортран 90/95 и Си++ отсутствуют. Правда, следует сказать, что Фортран-DVM базируется на расширенном языке Фортран 77, уже включающем в себя ряд возможностей Фортрана 90, и планируется дальнейшее такое расширение.
3. Эффективность выполнения параллельных программ
Эффективность выполнения программ всегда являлась очень важным фактором, определявшим в значительной степени успех и распространение языков программирования, предназначенных для создания вычислительных программ.
Джон Бэкус [17] выразил эту
мысль примерно следующими словами:
“Если бы в первые месяцы после появления
компилятора с языка Фортран он при
трансляции представительных
вычислительных программ генерировал бы
коды, выполняющиеся в два раза медленнее
написанных на ассемблере программ, то
распространение языка Фортран было бы под
угрозой”.
В настоящее время, когда распараллеливание программы ускоряет ее выполнение в сотни раз, а трудоемкость создания параллельных программ является основным препятствием для широкого использования высокой производительности современных вычислительных систем, эффективность выполнения программ по-прежнему остается важным фактором при выборе программистом того или иного подхода для разработки параллельных программ.
Ниже приводятся данные об эффективности выполнения шести тестов из пакета NPB 2.3 (BT, CG, FT, LU, MG, SP), реализованных с использованием подходов, выбранных для сравнительного анализа.
Эти тесты хорошо отражают характер вычислительных задач различных классов, за исключением задач с нерегулярными сетками. Два других теста из пакета NPB 2.3 (IS и EP) не использовались авторами исследований по той причине, что первый из них написан на языке Си и не является представительным (параллельная сортировка целых чисел), а второй служит для демонстрации абсолютного параллелизма и его распараллеливание ни у кого никаких проблем не вызывает.
Ниже дается краткая характеристика тестов, и приводятся их размеры в строках для трех версий каждой программы – последовательной версии, MPI-версии и DVM-версии. Информации о размерах HPF-версий и OpenMP-версий нет, но можно предполагать, что они незначительно отличаются от размеров DVM-версий.
|
Тест |
Характеристика теста |
SEQ |
MPI |
DVM |
MPI/ |
DVM/SEQ |
|
BT |
3D
Навье-Стокс, метод
переменных направлений |
3929 |
5744 |
3991 |
1.46 |
1.02 |
|
CG |
Оценка наибольшего собственного значения симметричной разреженной матрицы |
1108 |
1793 |
1118 |
1.62 |
1.01 |
|
FT |
Быстрое
преобразование Фурье, 3D спектральный метод |
1500 |
2352 |
1605 |
1.57 |
1.07 |
|
LU |
3D Навье-Стокс, метод
верхней релаксации |
4189 |
5497 |
4269 |
1.31 |
1.02 |
|
MG |
3D
уравнение Пуассона, метод Multigrid |
1898 |
2857 |
2131 |
1.50 |
1.12 |
|
SP |
3D Навье-Стокс, Beam-Warning approximate factorization |
3361 |
5020 |
3630 |
1.49 |
1.08 |
|
S |
|
15985 |
23263 |
17021 |
1.46 |
1.06 |
SEQ
–
поcледовательная программа
MPI
–
параллельная программа на языке Фортан
77 + MPI
DVM –
параллельная программа на языке
Фортран-DVM
Использованные в приведенных ниже диаграммах данные, заимствованные из различных источников, были получены на разных параллельных системах (данные о HPF и OpenMP получены на одной системе, но с интервалом в один год). Тем не менее, они позволяют сделать достаточно объективные выводы.
В приведенных диаграммах используются следующие обозначения:
· Speedup – ускорение выполнения параллельной программы на нескольких процессорах по отношению к ее выполнению на одном процессоре.
· Efficiency – эффективность параллельного выполнения, равная отношению ускорения к числу процессоров.
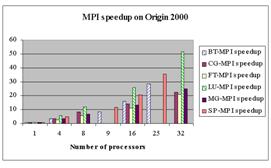
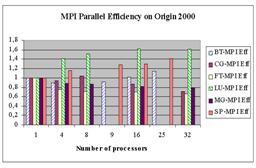
Ниже для
каждого теста
приведены отношения времени выполнения
его MPI-версии
к времени выполнения версии
этого теста, разработанной с
использованием четырех других подходов (HPF,
OpenMP, OpenMP+MPI,
DVM).
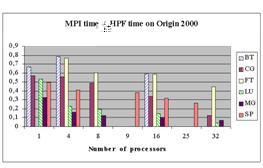
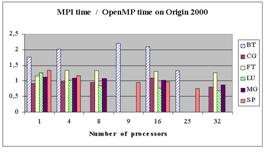
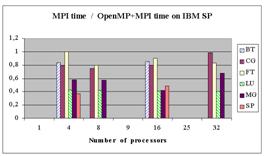
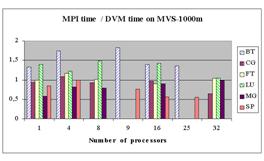
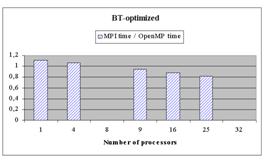
Диаграммы показывают, что MPI-программы, как правило, выполняются быстрее остальных. При этом, как правило, разрыв увеличивается по мере роста числа процессоров.
Не совсем понятно, почему так медленно выполняются HPF-программы на одном процессоре, по сравнению с DVM-программами. Возможны следующие объяснения этому факту:
· Аппаратные особенности процессора R10000, используемого в ЭВМ Origin 2000;
· Неудачные алгоритмы компиляции.
Большой проигрыш при увеличении числа процессоров объясняется принципиальными недостатками HPF-подхода.
На первый взгляд, кажется противоречивым то, что на некоторых программах OpenMP имеет преимущество над MPI, а OpenMP+MPI на них проигрывает MPI. Выигрыш OpenMP объясняется очень просто – при реализации тестов была проведена их оптимизация. Такая же оптимизация может быть проведена и в MPI-программах. Разработчики тестов на OpenMP приводят дополнительные данные о сравнении оптимизированных MPI-версии и OpenMP-версии BT.
Аналогичные оптимизации, связанные с понижением рангов рабочих массивов, были проведены также для OpenMP-версий программ SP и FT.
При использовании же подхода OpenMP+MPI никаких оптимизаций не делалось, а просто в MPI-программу для отдельного узла вставлялись директивы OpenMP. Отсюда довольно неожиданный вывод – даже на мультипроцессоре с 4 процессорами на общей памяти, используемом в качестве узла IBM SP, OpenMP проигрывает на регулярных программах MPI-подходу. Это объясняется лучшей локализацией доступа к данным в MPI-программе, что приводит к более эффективному использованию кэш-памяти.
На диаграммах наблюдается, что OpenMP-программы хуже масштабируются, чем MPI-программы. Авторы объясняют это отсутствием многомерного распараллеливания в используемой ими версии компилятора OpenMP, а также используемым в MPI-программах совмещением коммуникаций с вычислениями.
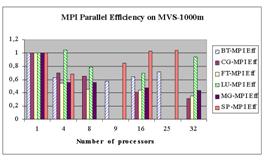
Эффективность DVM-программ гораздо выше, чем эффективность HPF, и вполне сравнима с эффективностью OpenMP и MPI. Невысокая эффективность на 32 процессорах программ CG и FT объясняется тем, что размерность задачи (класс А) слишком мала для такого числа быстрых процессоров (Alpha 21264, 667 МГц), из которых состоит ЭВМ МВС-1000М [21]. Это подтверждается и низкой эффективностью параллельного выполнения на этих процессорах соответствующих MPI-тестов (менее 0,4).
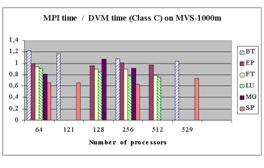
Для оценки масштабируемости DVM-программ приведены данные о соотношении времен выполнения MPI-версий и DVM‑версий тестов BT, EP, FT, LU, MG и SP класса С (тесты этого класса ориентированы на высокопроизводительные параллельные системы, требуют много памяти и поэтому не могут выполняться на малом числе процессоров).
Из них следует, что для всех тестов, кроме BT, эффективность DVM-версий составляет не менее 60% от эффективности MPI-версий.
Конечно, сравнение на тестах NPB 2.3 не вполне правомерно – они написаны на очень высоком профессиональном уровне и являются объектом пристального внимания многих специалистов. При разработке реальных параллельных программ, как правило, достижение высокой эффективности требует многократных изменений программы для поиска наилучшей схемы ее распараллеливания. Успешность такого поиска определяется простотой модификации программы. Кроме того, прикладному программисту трудно реализовать многие часто используемые приемы распараллеливания так же эффективно, как они реализуются системами программирования. Поэтому на реальных программах MPI-подход, как правило, проигрывает по эффективности DVM-подходу.
4. Переносимость и повторное использование параллельных программ
В настоящее время, когда программист имеет возможность запускать свою программу на разных, порою географически удаленных параллельных системах, важность переносимости программ (их способности выполняться на различных вычислительных системах с приемлемой эффективностью) трудно переоценить.
Создать для новых параллельных систем прикладное программное обеспечение, необходимое для решения важнейших научно-технических задач, вряд ли возможно без повторного использования уже созданных программ, без накопления и использования богатых библиотек параллельных программ.
Поэтому переносимость программ и их способность к повторному использованию должны рассматриваться как самые первостепенные показатели качества параллельных программ.
Как уже говорилось выше, широкое внедрение MPI обеспечило переносимость программ, разрабатываемых в рамках MPI-подхода для однородных кластеров.
Библиотеки MPI имеются не только на всех мультикомпьютерах, но и на всех мультипроцессорах. К сожалению, многие из этих библиотек недостаточно отлажены, что вызывает иногда серьезные проблемы у пользователей. Можно предъявить претензии и к эффективности многих библиотек (особенно свободно распространяемых). Из-за того, что те или иные коммуникационные операции в разных библиотеках заметно различаются по эффективности выполнения, прикладному программисту очень часто приходится изменять свою программу, чтобы обеспечить приемлемую эффективность ее выполнения при переходе на новую параллельную систему.
Однако перенос MPI-программ на неоднородные (по производительности процессоров) кластеры и сети ЭВМ приведет к заметной потере их эффективности, поскольку прикладной программист фактически не имеет возможностей для написания программ, способных настраиваться на производительность разных процессоров.
Еще хуже обстоят дела с повторным использованием MPI-программ. Очень сложно разрабатывать программы, способные выполняться на различном числе процессоров с разными по объему данными. Многие программисты предпочитают иметь разные варианты программ для разных конфигураций данных и процессоров, а также иметь отдельный вариант программы для работы на однопроцессорной ЭВМ. В таких условиях использование чужой программы представляется гораздо менее вероятной, чем это было на традиционных ЭВМ.
Но главные трудности связаны с отсутствием в языке программирования такого понятия, как распределенный массив. Вместо такого единого массива в программе используется на каждом процессоре свой локальный массив. Их соответствие исходному массиву, с которым программа имела бы дело при ее выполнении на одном процессоре, зафиксировано только в голове программиста и, возможно, в комментариях к программе.
Отсутствие в языке понятия распределенного массива является серьезным препятствием для разработки и использования библиотек стандартных параллельных программ. В результате, каждая такая библиотека вынуждена вводить свое понятие распределенного массива и реализовывать свой набор операций над ним. Однако вызов таких стандартных программ из прикладной программы требует от программиста согласования разных представлений распределенных массивов.
Таких принципиальных проблем с повторным использованием параллельных программ нет, если эти программы разрабатываются в рамках подходов HPF, OpenMP или DVM. Более того, в рамках этих подходов можно обеспечить удобный вызов стандартных параллельных программ, разработанных на других языках и входящих в состав известных библиотек (для которых известно их внутреннее представление распределенных массивов). Например, можно позволить вызывать функции пакета ScaLAPACK [22] из HPF-программ или DVM-программ.
Переносимость HPF-программ определяется наличием компилятора HPF для конкретной параллельной системы, а точнее для процессора, используемого в узлах этой системы. Поскольку качественных и свободно распространяемых компиляторов, способных генерировать программы для всех процессоров, нет, то при переносе HPF-программ на некоторые платформы возникнут серьезные проблемы.
К сожалению, HPF-программу нельзя компилировать и выполнять на последовательных ЭВМ в среде компиляторов Фортран 77/90, что является дополнительным препятствием для внедрения этого языка.
С переносимостью OpenMP-программ на DSM-кластеры проблем нет, поскольку для всех основных микропроцессоров соответствующие компиляторы или уже имеются, или появятся в ближайшее время. Кроме того, эти программы без каких-либо изменений могут компилироваться и выполняться на последовательных ЭВМ в среде компиляторов Фортран 77/90 или Си, Си++. Однако перенос на DM-кластеры и сети ЭВМ вызывает принципиальные сложности и, по-видимому, в ближайшие годы невозможен.
DVM-программы, также без каких-либо изменений, могут компилироваться и выполняться на последовательных ЭВМ в среде компиляторов Фортран 77/90 или Си.
Переносимость DVM-программы на произвольные кластеры или сети ЭВМ обеспечивается тем, что она преобразуется в программу на языке Фортран 77 (или Си), содержащую вызовы функций системы поддержки, которая для организации межпроцессорного взаимодействия использует библиотеку MPI. Такая программа может выполняться всюду, где есть MPI и компиляторы с языков Си и Фортран 77.
Кроме того, программы на языке Фортран-DVM могут автоматически конвертироваться в программы на языке HPF или HPF2. Планируется в дальнейшем обеспечить и автоматическое преобразование DVM-программ в OpenMP-программы.
5. Средства отладки
Отладка параллельной программы является процессом более трудоемким, чем отладка последовательной программы. Причиной этого является не только сложность параллельной программы, но и ее недетерминированное поведение, серьезно затрудняющее и функциональную отладку (достижение правильности результатов), и отладку эффективности программы. Раньше с подобными трудностями сталкивались, в основном, разработчики операционных систем и систем реального времени, которые сами и создавали для себя специальные средства отладки. Развитые средства отладки могут существенно упростить разработку параллельных программ прикладными программистами.
Большинство современных средств отладки параллельных программ основано на представлении программы как совокупности выполняющихся процессов.
Средства функциональной отладки, как правило, предоставляют тот же набор примитивов, что и обычные последовательные отладчики, расширенный с учетом специфики параллельного выполнения. Сюда входят следующие базовые примитивы:
· инициализация выполнения программы;
· завершение программы;
· приостановка и продолжение выполнения программы;
· задание точки останова, проверка заданных условий, просмотр и модификация значений переменных;
· пошаговое исполнение.
Кроме того, широко используются средства накопления и анализа трассировки.
Наиболее развитыми системами функциональной отладки MPI-программ являются TotalView [23] и PGDBG [24].
При отладке эффективности используются разного рода профилировщики, выдающие после завершения программы информацию о временах вычислений, обменов сообщениями и синхронизации. Примерами таких систем, используемых для анализа эффективности MPI-программ, являются: Nupshot [25], Pablo [26], Vampir [27].
Несмотря на обилие различных инструментов для отладки MPI-программ положение дел в этой области нельзя признать удовлетворительным по следующим причинам.
Во-первых, каждая система отладки предоставляет свой набор возможностей и свой интерфейс с пользователем.
Во-вторых, каждая достаточно развитая система ориентирована на работу с конкретными компиляторами и библиотеками MPI. В результате, при переходе пользователя на другую машину, вероятнее всего, он не найдет там привычной для него системы отладки.
Чтобы стандартизировать интерфейс отладчиков с пользователем, в 1997 году начал свою работу High Performance Debugging Forum (HPDF). Результатом работы этого форума стала первая версия стандарта HPD, которая определяет командный интерфейс параллельных отладчиков [28].
Проводится работа и по стандартизации трассировочной информации, чтобы ликвидировать зависимость анализаторов производительности от библиотек, обеспечивающих сбор информации о выполнении программы.
Однако, поскольку разработчики имеющихся систем отладки, как правило, стараются обеспечить их использование с разными компиляторами и даже с разными моделями программирования, то трудно ожидать в ближайшем будущем реальной унификации средств отладки. Тем более что изменения архитектуры процессоров и параллельных систем постоянно ставят все более сложные задачи для анализаторов производительности.
Некоторые из систем отладки MPI-программ были адаптированы для отладки HPF-программ, например отладчик TotalView, профилировщики Pablo и PGPROF [29]. При этом надо подчеркнуть, что отсутствие ясной модели выполнения HPF-программ не только сильно затрудняет отладку их эффективности, но и является серьезным препятствием для организации взаимодействия пользователя со средствами отладки производительности в терминах языка HPF.
Отладчик TotalView используется и для отладки OpenMP-программ. Для поиска в OpenMP-программах некорректных распараллеливающих директив используется статический анализатор, входящий в состав системы KAP/Pro Toolset [30]. Эта же система предоставляет и средства анализа производительности OpenMP-программ.
Анализируя подходы HPF, OpenMP и DVM, базирующиеся на использовании единой программы с единым пространством имен и единым адресным пространством, можно заметить, что с точки зрения функциональной отладки программ они имеют следующие общие свойства.
Во-первых, задаваемая программистом и используемая при распараллеливании информация о свойствах программы, которую невозможно извлечь на стадии компиляции, может быть проверена при выполнении программы. Это позволяет автоматически выявлять целый ряд ошибок, поиск которых традиционными методами очень сложен.
Во-вторых, способность одной и той же программы выполняться и в последовательном и в параллельном режиме, позволяет использовать для ее отладки метод автоматического сравнения результатов выполнения в разных режимах, что существенно упрощает поиск ошибок, проявляющихся только при параллельном выполнении программы.
Поэтому для указанных подходов можно использовать следующую методику поэтапной отладки программ.
На первом этапе программа отлаживается на рабочей станции как последовательная программа, используя обычные методы и средства отладки. На втором этапе программа выполняется на той же рабочей станции в специальном режиме проверки распараллеливающих указаний. На третьем этапе программа может быть выполнена на параллельной машине в специальном режиме, когда промежуточные результаты параллельного выполнения сравниваются с эталонными результатами (например, результатами последовательного выполнения).
Такая методика функциональной отладки используется в системе DVM. Для обеспечения второго и третьего этапов этой методики служит специальный DVM-отладчик.
Для отладки эффективности DVM-программ используется анализатор производительности, который позволяет пользователю получить информацию об основных характеристиках эффективности выполнения его программы (или ее частей) на параллельной системе.
Для облегчения отладки эффективности можно использовать специальный инструмент - предиктор, позволяющий на рабочей станции смоделировать выполнение DVM-программы на параллельной ЭВМ с заданными параметрами (топологии коммуникационной сети, ее пропускной способности, а также производительности процессоров) и получить прогнозируемые характеристики эффективности ее выполнения.
Явным недостатком средств отладки системы DVM является отсутствие графического многооконного интерфейса, позволяющего в наглядной форме представить информацию об обнаруженных ошибках и о характеристиках эффективности, а также их привязку к исходным текстам программы.
6. Выводы
На основании проведенного анализа пяти различных подходов к разработке параллельных программ для вычислительных кластеров и сетей ЭВМ (MPI, HPF, OpenMP, OpenMP+MPI и DVM) можно сделать следующие выводы.
1. С точки зрения простоты разработки параллельных программ и их повторного использования явное преимущество имеют подходы HPF, OpenMP и DVM. Конечно, очень трудно количественно оценить это преимущество, но в качестве грубой оценки сложности программирования вполне годятся данные о соотношении количества дополнительных операторов, которые пришлось при распараллеливании тестов NPB 2.3 добавить в их последовательные версии – 40% для MPI и 4% для DVM. Следует отметить при этом, что дополнительные операторы DVM-программы являются простыми спецкомментариями, не зависящими от размеров массивов и числа процессоров. Дополнительный код MPI-программы представляет собой сложную систему программ управления передачей сообщений, зависящих от размеров массивов и числа процессоров. Данные для HPF и OpenMP отсутствуют, но они должны быть близки по этому показателю к DVM-подходу.
2. По эффективности выполнения программ HPF заметно отстает от остальных подходов.
3. OpenMP ограничивает переносимость программ мультипроцессорами и DSM-кластерами.
4. Гибридный подход OpenMP+MPI, как и MPI, не может обеспечить эффективного выполнения программ на неоднородных кластерах и сетях ЭВМ.
Таким образом, ни один из четырех подходов (MPI, HPF, OpenMP и OpenMP+MPI), базирующихся на имеющихся стандартах, не может рассматриваться в настоящее время как вполне подходящий для разработки параллельных программ для вычислительных кластеров и сетей ЭВМ. Эту точку зрения разделяют многие ведущие специалисты в области параллельных вычислений.
Наверное, пройдет еще немало лет до появления языка программирования, который будет принят сообществом программистов в качестве языка разработки параллельных программ для высокопроизводительных вычислений на кластерах и сетях ЭВМ. Возможно, это будет HPF3, расширенный моделью параллелизма по управлению, или значительно переработанный OpenMP, расширенный моделью параллелизма по данным. Очень вероятно, что этот новый язык будет во многом похож на языки системы DVM.
А как же разрабатывать программы для вычислительных кластеров все эти годы до появления нового языка?
Можно использовать MPI, понимая при этом, что будут затрачены большие усилия для написания, отладки и сопровождения программ, которые когда-то все равно придется переписывать на другом языке.
Можно попробовать использовать DVM, поскольку освоение этого подхода может существенно сократить время написания, отладки и сопровождения программ. А в случае появлении нового стандарта языка, DVM-программы могут быть преобразованы в программы на новом языке автоматически, или с минимальным участием программиста.
Список литературы
1.
2.
Андрианов
А.Н., Ефимкин К.Н., Задыхайло И.Б.
Язык Норма. Препринт ИПМ им. М.В.Келдыша
АН СССР, № 165, 1985.
3.
Zadykhailo I.B., Krukov V.A.
and Pozdnjakov L.A. 'RAMPA - CASE for portable parallel programs development'',
Proc. of the International Conference on Parallel Computing Technologies,
4.
Konovalov N.A., Krukov
V.A., Mihailov S.N. and Pogrebtsov
A.A. Fortran DVM - a Language for Portable Parallel Program Development.
Proceedings of Software For Multiprocessors & Supercomputers: Theory,
Practice, Experience. Institute for System Programming, RAS,
5.
Lastovetsky A. mpC - a
Multi-Paradigm Programming Language for Massively Parallel Computers, ACM
SIGPLAN Notices, 31(2):13-20, February 1996.
6.
Abramov S., Adamovitch A. and
Kovalenko M. T-system: programming environment providing automatic dynamic
parallelizing on IP-network of Unix-computers. Report on 4-th International
Russian-Indian seminar and exibition,
7.
Message-Passing Interface
Forum, Document for a Standard Message-Passing Interface, 1993. Version 1.0. http://www.unix.mcs.anl.gov/mpi/
8.
Message-Passing Interface Forum, MPI-2: Extensions to the Message-Passing
Interface, 1997. http://www.unix.mcs.anl.gov/mpi/
9.
High Performance Fortran
Forum. High Performance Fortran Language Specification. Version 1.0, May 1993.
10.High Performance Fortran Forum. High Performance Fortran Language
Specification. Version 2.0, January 1997.
11.OpenMP Consortium: OpenMP Fortran Application Program Interface, Version
1.0, October 1997. http://www.openmp.org/
12.DVM-система.
http://www.keldysh.ru/dvm/
13.Bailey D., Harris T., Saphir W., Van der Wijngaart, Woo A., Yarrow M.The
NAS Parallel Benchmarks 2.0. NAS Technical Report NAS-95-020,
14.PCF Fortran. Version 3.1. Aug.1, 1990.
15.Hiranandani S., Kennedy K., Tseng C. Compiling Fortran D for MIMD
Distributed-Memory Machines. Comm. ACM, Vol. 35,No. 8 (Aug. 1992), 66-80.
16.Коновалов
Н.А., Крюков В.А., Любимский Э.З. Управляемая
виртуальная память.Программирование, №1,
1977.
17.Backus J. The history of FORTRAN I, II and III. ACM SIGPLAN Notices,
13(8):165-180,1978.
18.Frumkin M., Jin H., and Yan J.
Implementation of NAS Parallel Benchmarks in High Performance Fortran. NAS
Technical Report NAS-98-009,
19.Frumkin M., Jin H., and Yan J. The OpenMP
Implementation of NAS Parallel Benchmarks and Its Performance. NAS Technical
Report NAS-99-011,
20.Capello F., Etiemble D. MPI versus MPI+OpenMP
on the IBM SP for the NAS Benchmarks. In Proceedings
of Supercomputing ’2000, 2000.
21.Елизаров
Г.С., Забродин
А.В., Левин В.К., Каратанов
В.В., Корнеев В.В.,
Савин Г.И., Шабанов Б.М. Структура
многопроцессорной вычислительной системы
МВС-1000М. Труды Всероссийской научной
конференции "Высокопроизводительные
вычисления и их приложения", г.Черноголовка,
30 октября - 2 ноября 2000 г., Изд-во Московского
университета, 2000.
22.Dongarra J., Walker D., and others. ScaLAPACK
Users’ Guide.
23.TotalView. http://www.etnus.com/Products/TotalView/index.html
24.Portland Group Debugger. http://www.pgroup.com
25.Nupshot . http://www.mcs.anl.gov/mpi/mpich/
26.Pablo. http://www-pablo.cs.uiuc.edu
27.Vampir. http://www.pallas.de/pages/vampir.htm
28.HPD Version 1 Standard: Command Interface for Parallel Debuggers:
Technical Report CSTR-97 / High Performance Debugging Forum; ed. Pancake C.,
Francioni J. – Dept. of Computer Science,
29.Portland Group Profiler. http://www.pgroup.com
30.KAP/Pro Toolset, “Assure/Guid Reference Manual”,Kuck &
Associates,Inc.1997.
http://www.etnus.com/Products/TotalView/index.html