| DVM debugger - contents | Part 1 (1 - 4) | Part 2 (5 - 6.4) | Part 3 (6.5) | Part 4 (7) |
| document data: March 2000 | - last edited 22.05.01 - |
1 The Functions of DVM debugger
DVM debugger is used for debugging DVM-program (written in Fortran-DVM or C-DVM languages). The following approach is used to debug DVM-programs. First, the program is debugged on a workstation as a sequential program using ordinary debugging methods and tools. Then the program is executed at the same workstation in the special mode of checking DVM-directives. At the next step the program may be executed on a parallel computer in the special mode, when intermediate results of its execution are compared with reference results (for example, the results of its sequential execution).
The DVM-program can contain the errors of different kinds. The DVM-debugger is used to detect errors not appeared during a sequential execution.
In the common case the following classes of errors can be considered:
A compiler detects the errors of the first class.
Only simple errors of second class such as wrong parameter type may be detected by static analysis. To detect the errors of this class each Lib-DVM function checks the correctness of DVM-directives order and parameters. The checks are done dynamically, during program execution. Some of the checks can cause considerable overhead and therefore are performed by special request.
It is impossible to detect errors of third class without special compilation mode and considerable overhead in the parallel program. Unspecified data dependence in parallel loop is example of the error of the third class. To detect this error it is necessary to fix all data modifications and usage on different processors and to determine the cases, when a variable is modified on one processor and used on the other. This detection can be more effectively performed on a single processor by emulation of parallel execution of the program.
The DVM-debugger is intended to detect errors of third class. It is based on the following two methods.
The first method, method of dynamic control of DVM-directives, allows verifying the correctness of the program parallelization specified by DVM-directives. It is based on the analysis of a sequence of Lib-DVM function calls and references to the variables during parallel program execution simulated on a single processor.
The second method is based on the comparison of parallel and sequential program execution trace results. It allows to localize the program point and moment, when the results are beginning to differ because of incorrect specification of parallelism by DVM-directives or an error of sequential algorithm, appeared only during parallel execution. Unlike the first method, only part of program can be compiled in the special debug mode.
The facilities of parallel program tracing that are included into DVM-debugger may be also useful to detect errors of fourth class. Moreover the system tracing facilities are intended to detect these errors (the tracing of DVM Run-Time library calls).
1.1 The “Dynamic control of DVM-directives” method
The dynamic control is based on simulation of DVM-program parallel execution on a single processor. This method using can slow down the program execution significantly and requires large volumes of additional memory. Therefore it can be applicable to a program with specially chosen test data only.
The dynamic control allows to detect the following kinds of errors:
1.3 The “Comparing execution results” method
First of all the dynamic control is intended to check DVM-directives correctness. The control area is limited by DVM-programs compiled in the special debug mode only. However, the program can contain calls of procedures written in ordinary sequential languages (including assembler). The procedure execution is not controlled and can cause incorrect parallel execution of the program. Besides, correctness of reduction operation descriptions is not checked. And finally, the program can have errors (not related with its parallelization) which appear only during a parallel execution.
To detect such errors another control method is provided. This method is based on an accumulation of trace results for different conditions of execution and these results comparison. When using this method the program may be executed in two modes. In the first mode, trace results (intermediate variable values) are accumulated and written to a file as the reference trace results. In the second mode, execution results are compared with the reference ones taking into account that values of some variables may differ (for example, values of reduction variables inside parallel construction).
The DVM-debugger consists of two parts: the dynamic control system and the trace comparison system.
Both systems use the following base subsystems: tables allowing storing large volumes of uniformed information, hash-tables for fast data lookup by key, and diagnostic output module.
Other systems of higher level are based on these two subsystems.
The dynamic control system consists of the following components:
The trace comparison system consists of the following components:
3 Prototypes of debugger functions
The Lib-DVM system contains additional system functions relating to dynamic debugger that are responsible for dynamic control and comparing of execution results. The C-DVM and Fortran-DVM compilers insert calls of these functions in special debugging mode.
The prototypes of debugger functions is the following:
| long dprstv_(long
*TypePtr, AddrType *addr, long *Handle, char *Operand, long OperLength) |
| TypePtr | – | variable type (rt_INT, rt_LONG, rt_FLOAT or rt_DOUBLE). The function call is ignored for tracing if other type is specified; |
| addr | – | address of the variable or array element; |
| Handle | – | handle of DVM-array if array element is specified. Otherwise, the argument should be equal to NULL; |
| Operand | – | operand name. This name is reported in the trace file and error messages; |
| OperLength | – | length of the Operand. This parameter is required for Fortran compatibility. It should be equal to –1 if the C language is used. |
The function marks beginning of a variable or array element modification. The call should be inserted before a variable modification and up to an evaluation of expression to be assigned. The system call should be accompanied by dstv_ ().
| long dstv_(void) |
The function marks the completion of a variable or array element modification. The call should be inserted after a variable modification and should be conjugate with dprstv_().
| long dldv_(long *TypePtr,
AddrType *addr, long *Handle, char *Operand, long OperLength) |
||
| TypePtr | – | variable type (rt_INT, rt_LONG, rt_FLOAT or rt_DOUBLE). The function call is ignored for tracing if other type is specified; |
| addr | – | address of the variable or array element; |
| Handle | – | handle of DVM-array if array element is specified. Otherwise, the argument should be equal to NULL; |
| Operand | – | operand name. This name is reported in the trace file and error messages; |
| OperLength | – | length of the Operand. This parameter is required for Fortran compatibility. It should be equal to –1 if the C language is used. |
The function marks access to a variable or array element for reading.
| long dbegpl_(long *Rank, long *No, long *Init, long *Last, long *Step) | ||
| Rank | – | rank of a parallel loop; |
| No | – | the number of structure. It should be unique for all loops and all task regions inside the program; |
| Init | – | Rank-dimensional array of initial values of iteration variables; |
| Last | – | Rank-dimensional array of last values of iteration variables; |
| Step | – | Rank-dimensional array of iteration variables steps. |
The function marks parallel loop beginning. The function should be called before mapping the parallel loop on the abstract machine.
| long dbegsl_(long *No) | ||
| No | – | the number of structure. It should be unique for all loops and all task regions inside the program. |
The function marks sequential loop beginning. The sequential loop rank is always equal to 1.
| long dbegtr_(long *No) | ||
| No | – | the number of structure. It should be unique for all loops and all task regions inside the program. |
The function marks task region beginning. The task region rank is always equal to 1.
| long dendl_(long *No, unsigned long *Line) | ||
| No | – | number of completed structure; |
| Line | – | the structure exit line number. It is used to check a correctness of parallel loop completion. |
The function marks completion of a sequential or parallel loop or task region. The function should be called after completion of the last iteration of the loop or last parallel task in task region.
| long diter_(AddrType *index) | ||
| index | – | array of pointers to iteration variables. The array rank should be equal to rank of the executed structure. |
The function marks beginning of new iteration of a sequential or parallel loop or beginning of new parallel task. The function should be called after modification of all iteration variables of the loop (for multidimensional loops). For task region the variable, containing a number of current executed parallel task should be passed as the function argument.
| long drmbuf_(long* ArrSrc, AddrType* RmtBuff, long* Rank, long* Index) | ||
| ArrSrc | – | a handle of source array for which the remote access buffer is created; |
| RmtBuff | – | an address of a scalar variable, if buffer is created for a single element of the array, or a handle of DVM-array to be used as a buffer, if the buffer is created for a sub-array; |
| Rank | – | remote access buffer rank. It should be zero if buffer is created for a single array element. |
| Index | – | an array that contains indexes of the cut (selected) dimensions. If an element of this array is not equal to –1, the range appropriate to the given array element is used. Otherwise, the whole dimension of the array is used. |
The function marks remote access buffer creation for dynamic control system. This call is necessary to correct monitoring of access to the elements of a DVM-array through the remote access buffer. The call should be used after creation of the buffer and initialization of its elements.
| long dskpbl_(void) |
The function marks the completion of own computation block in sequential branch of the program. The function should be called after execution of corresponding statement group.
The table is intended to keep large volume of data. A peculiarity of the implementation is that the memory is allocated not for each element but for several ones. The number of elements the memory will be allocated for is defined by parameters of table initialization. The table is expanded automatically, when the current allocated memory block is exhausted.
The following structure is defined for the table:
| typedef struct tag_TABLE | ||||
| { | ||||
| byte | IsInit; | |||
| s_COLLECTION | cTable; | |||
| size_t | TableSize; | |||
| size_t | CurSize; | |||
| size_t | ElemSize; | |||
| PFN_TABLE_ELEMDESTRUCTOR | Destruct; | |||
| } | TABLE; | |||
| IsInit | – | flag of the table initialization. It is used for postponed initialization improve performance; | ||
| cTable | – | a set of pointers to allocated memory blocks; | ||
| TableSize | – | number of elements to allocate when the table is expanded; | ||
| CurSize | – | number of used elements in the current table block; | ||
| ElemSize | – | size in bytes of one element; | ||
| Destruct | – | pointer to the
function with prototype void (*PFN_TABLE_ELEMDESTRUCTOR)(void *Elem). This function is called for each table element when it is removed from the table. |
||
The following calls are intended for work with the table:
| void table_Init(TABLE *tb, size_t TableSize, size_t ElemSize, PFN_TABLE_ELEMDESTRUCTOR Destruct) |
| tb | – | pointer to the TABLE structure to be initialized; |
| TableSize | – | number of the elements to be allocated when expanding the table; |
| ElemSize | – | size in bytes of one table element; |
| Destuct | – | pointer to table element destructor-function. It can be NULL. |
Table initialization. This function should be called before using the table.
| void table_Done( TABLE *tb ) | ||
| tb | – | pointer to the TABLE structure. |
Table destructor. This function should be called upon usage of the table to free allocated memory. It calls element destructor for each element of the table.
| long table_Count( TABLE *tb ) | |||
| tb | – | pointer to the TABLE structure. | |
The function returns number of used table elements.
| void *table_At( TABLE *tb, long No ) | ||||
| tb | – | pointer to the TABLE structure; | ||
| No | – | zero based element number. The program will aborted if the No does not fall to number of elements range. | ||
The function returns the pointer to the specified table element.
| long table_Put( TABLE *tb, void *Struct ) | |||
| tb | – | pointer to the TABLE structure. | |
| Struct | – | pointer to the inserted element. Only ElemSize bytes will be copied into the table. | |
The function inserts a new element into the table.
| void *table_GetNew( TABLE *tb ) | ||||
| tb | – | pointer to the TABLE structure. | ||
The function allocates a space for new element into the table and returns a pointer to this memory. The function is more effective then table_Put() because no memory copy operation is performed.
| void table_RemoveFrom( TABLE *tb, long Index ) | ||||
| tb | – | pointer to the TABLE structure. | ||
| Index | – | element number from which elements will be removed. | ||
The function removes elements of the table starting from number Index+1. The element with the number Index itself remains in the table.
| void table_RemoveAll( TABLE *tb ) | ||
| tb | – | pointer to the TABLE structure. |
The function removes all elements from the table and frees allocated memory.
| void table_Iterator(TABLE
*tb, PFN_TABLEITERATION Proc, void *Param1, void *Param2) |
| tb | – | pointer to the TABLE structure. |
| Proc | – | iteration function with the
following prototype: void (*PFN_TABLEITERATION)( void *Elem, void *Param1, void *Param2 ). This function will be called for each element of the table. |
| Param1 | – | the parameter passed as Param1 into the Proc function. |
| Param2 | – | the parameter passed as Param2 into the Proc function. |
The function applies the same operation to each element of the table.
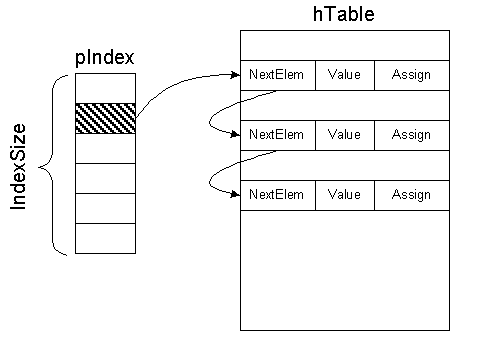
The hash-table is intended to fast lookup of records by a key. The hash-table is organized as an index of fixed size and chains of records, associated with each element of the index. Each record contains a value, placed into the hash-table, its key and pointer to the next record in the chain.
When new element is placed into the hash-table, hash-value in [0, IndexSize] range is calculated for its key. This value is a number of the element in the index of the hash-table, the pointer to new element of the chain will be placed into. Previous pointer is kept in placed element.
The search is performed as follows. The hash-value is calculated using the key. The pointer to the first element of the chain is extracted from the index by the hash-value. Then all elements of the chain is examined and compared with target element by the specified key. If the keys are matched, the found element is returned as result of the search.
The following algorithms can be used to calculate hash-values:
The following picture schematically shows realization of hash-table:
pIndex - index of hash-table
IndexSize - size of the index of hash-table
hTable - dynamic array, keeping hash-table elements
NextElem - pointer to the next element of the chain
Value - key of element
Assign - value, kept in the table and associated with the key
Figure 1. Foundation of hash-table
The following types are defined for the hash-table:
Hash-value:
| typedef size_t HASH_VALUE |
Data type, used for associative search. A hash-value is calculated by this type:
| typedef unsigned long STORE_VALUE |
Structure of the hash-table element:
| typedef struct tag_HashList |
| { | ||||
| long | NextElem; | |||
| STORE_VALUE | Value; | |||
| long | Assign; | |||
| } | HashList; | |||
| NextElem | – | the number of the next element of the chain. It is equal to zero for the last element of the chain; | ||
| Value | – | the element key. This key is used to access to the element; | ||
| Assign | – | the stored value. | ||
Structure of the hash-table:
| typedef struct tag_HASH_TABLE |
| { | ||||
| TABLE | hTable; | |||
| long * | pIndex; | |||
| size_t | IndexSize; | |||
| PFN_CALC_HASH_FUNC | HashFunc; | |||
| unsigned long * | pElements; | |||
| unsigned long | statCompare, statPut, statFind; | |||
| } | HASH_TABLE; | |||
| hTable | – | hash-table to keep hash-table elements;. | ||
| pIndex | – | the hash-index, an array containing starting indexes of the chains. The hash-value gives an index in the hash-index. | ||
| IndexSize | – | size of the pIndex array. | ||
| HashFunc | – | pointer to the function that calculates a hash-value by a key. | ||
| pElements | – | array that keeps chain sizes of corresponding pIndex elements. It is used to store statistics of using hash-table elements. | ||
| statCompare, statPut, statFind | – | statistics fields. These fields contain count of ‘compare’, ‘put’ and ‘find’ actions performed with the hash-table. | ||
The following functions are intended for working with hash-table:
| void hash_Init(HASH_TABLE *HT, size_t IndexSize, int TableSize, PFN_CALC_HASH_FUNC Func) |
| HT | – | pointer to HASH_TABLE structure to be initialized; | ||
| IndexSize | – | the size of the hash-index; | ||
| TableSize | – | hash-array increment value for hash-array expansion; | ||
| Func | – | pointer to the function that calculates hash-value. If Func is equal to NULL then the standard function StandartHashCalc will be applied. The function StandartHashCalc calculates hash-value using the following formula: <hash-value> = <key> % IndexSize. | ||
The function performs all required initialization operations for hash-table.
| void hash_Done( HASH_TABLE *HT ) | ||||
| HT | – | pointer to the HASH_TABLE structure. | ||
The function destructs the hash-table. The function frees all allocated memory for hash-table elements.
| long hash_Find( HASH_TABLE *HT, STORE_VALUE Val ) | ||||
| HT | – | pointer to the HASH_TABLE structure. | ||
| Val | – | the key of the element. | ||
The function finds a value by the specified key.
| void hash_Insert( HASH_TABLE *HT, STORE_VALUE Val, long Assign ) | ||||
| HT | – | pointer to the HASH_TABLE structure. | ||
| Val | – | the key of inserted element. | ||
| Assign | – | the value associated with the key. | ||
The function inserts a new element into the hash-table.
| void hash_Change( HASH_TABLE *HT, STORE_VALUE Val, long Assign ) | ||||
| HT | – | pointer to the HASH_TABLE structure. | ||
| Val | – | the key of changed element. | ||
| Assign | – | the value associated with the key. | ||
The function updates an associated value for the specified key.
| void hash_Remove( HASH_TABLE *HT, STORE_VALUE Val ) | ||||
| HT | – | pointer to the HASH_TABLE structure. | ||
| Val | – | the key of removed element. | ||
The function removes an element with the specified key.
| void hash_Iterator(HASH_TABLE *HT, PFN_HASHITERATION Proc, void *Param) | ||||
| HT | – | pointer to the HASH_TABLE structure; | ||
| Proc | – | iteration
function with the following prototype: void (*PFN_HASHITERATION)(long Elem, void *Param) where Elem is associated value of a hash-table element and Param is additional parameter. This function will be called for each hash-table element; |
||
| Param | – | parameter passed as Param into the Proc function. | ||
The function applies the same operation for all the hash-table elements.
| void hash_RemoveAll( HASH_TABLE *HT ) |
| HT | – | pointer to the HASH_TABLE structure. | ||
The function removes all elements from the hash-table.
The table of variables is intended to store information about variables and to fast access to it using the variable address.
Each element of a table of variables keeps the reference to the same variable at the previous level (if the variable is used at several levels), address of variable, class of using, and additional information that depends on class of using.
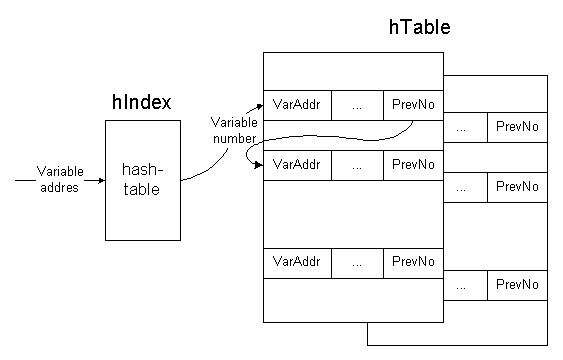
Figure 2. The variable-table representation
The following structure is used to store elements of table of variables:
| typedef struct tag_VarInfo |
| { | ||||
| byte | Busy; | |||
| void * | VarAddr; | |||
| long | PrevNo; | |||
| int | EnvirIndex; | |||
| byte | Type; | |||
| SysHandle * | Handle; | |||
| void * | Info; | |||
| int | Tag; | |||
| byte | IsInit; | |||
| PFN_VARTABLE_ELEMDESTRUCTOR | pfnDestructor; | |||
| } | VarInfo; | |||
| Busy | – | flag is equal 1 if this element contains valid variable information and 0 if variable is removed from the table of variables. This flag is used for work optimization and preventing frequent memory copying; | ||
| VarAddr | – | variable address; | ||
| PrevNo | – | the number of table of variables element that describes the same variable on a previous level; | ||
| EnvirIndex | – | number of the variable level; | ||
| Type | – | the class of variable using; | ||
| Handle | – | handle of a distributed array. It is not equal to zero if this element describes a distributed array; | ||
| Info | – | pointer to an additional variable information structure. It is depended on a variable type; | ||
| Tag | – | flag to store various variable attributes according to type of variable usage; | ||
| IsInit | – | flag of variable initialization. Is used for scalar variables; | ||
| pfnDestructor | – | pointer to variable description destructor. This function is called when variable is removed from the table of variables. It can be equal NULL. | ||
The following structure describes a variable table:
| typedef struct tag_VAR_TABLE |
| { | ||||
| HASH_TABLE | hIndex; | |||
| TABLE | vTable; | |||
| } | VAR_TABLE; | |||
| hIndex | – | hash-table. It is used for searching variable information by its address. | ||
| vTable | – | table used to keep variable information. | ||
The following functions are intended for work with table of variables:
| void vartable_Init(
VAR_TABLE *VT, int vTableSize, int hIndexSize, int
hTableSize, PFN_CALC_HASH_FUNC Func ) |
| VT | – | pointer to table of variables structure to be initialized; |
| vTableSize | – | size of vTable expanding; |
| hIndexSize | – | size of hash-index array of hIndex; |
| hTableSize | – | size of hash-table hIndex expanding; |
| Func | – | pointer to a function that calculates hash-value by variable address. |
The function initializes the table of variables.
| void vartable_Done( VAR_TABLE *VT ); | ||
| VT | – | pointer to table of variables structure. |
The function destructs table of variables.
| VarInfo *vartable_GetVarInfo( VAR_TABLE *VT, long NoVar ) | ||
| VT | – | pointer to table of variables structure; |
| NoVar | – | number of variable in the table of variables. |
The function returns the variable information from the table of variables by variable number. The NoVar should point to a valid table of variables element.
| VarInfo *vartable_FindVar( VAR_TABLE *VT, void * Addr ) | ||
| VT | – | pointer to table of variables structure; |
| Addr | – | variable address. |
The function returns the variable information from the table of variables by variable address. The function returns NULL if a variable with such address is not registered.
| long vartable_FindNoVar( VAR_TABLE *VT, void * Addr ) | ||
| VT | – | pointer to table of variables structure; |
| Addr | – | variable address. |
The function returns the variable number by variable address. The function returns –1 if a variable with such address is not registered.
| long
vartable_PutVariable(VAR_TABLE* VT, void* Addr, int Env,
byte Type, SysHandle* Handle, int Tag, void* Info, PFN_VARTABLE_ELEMDESTRUCTOR pfnDestructor) |
| VT | – | pointer to table of variables structure; |
| Addr | – | variable address; |
| Env | – | variable level; |
| Type | – | class of variable usage; |
| Handle | – | distributed array handle if distributed array is registered; |
| Tag | – | variable attributes; |
| Info | – | pointer to additional variable information; |
| pfnDestructor | – | pointer to variable information destructor. It can be NULL. |
The function registers of a new variable in the table of variables and returns a number of the registered variable.
| void vartable_VariableDone( VarInfo* Var ) | ||
| Var | – | pointer to variable information structure |
The function uninitializes variable information structure. The function sets the Busy flag to 0 and calls corresponding variable information destructor if available.
| void vartable_RemoveVariable( VAR_TABLE *VT, void * Addr ) | ||
| VT | – | pointer to table of variables structure. |
| Addr | – | variable address. |
The function removes variable information from the table of variables.
| void vartable_RemoveAll( VAR_TABLE *VT ); | |||
| VT | – | pointer to table of variables structure. | |
The function removes all variables from the table of variables.
| void vartable_RemoveVarOnLevel( VAR_TABLE *VT, int Level ) | ||||
| VT | – | pointer to table of variables structure. | ||
| Level | – | executed level | ||
The function removes all variables with the specified variable level.
| void vartable_Iterator( VAR_TABLE *VT, PFN_VARTABLEITERATION Func ) | ||
| VT | – | pointer to table of variables structure. |
| Func | – | iteration function with the
following prototype: void (*PFN_VARTABLEITERATION)( VarInfo * ). All the pointers to variable information structures from the variable table are passed to the function. |
The function applies the same operation for all the elements of the table of variables.
| void
vartable_LevelIterator(VAR_TABLE* VT, int Level, PFN_VARTABLEITERATION Func) |
| VT | – | pointer to table of variables structure. | ||
| Level | – | variable level | ||
| Func | – | iteration
function with the following prototype: void (*PFN_VARTABLEITERATION)( VarInfo * ). All the variable information structures of the table of variables with specified variable level are passed to the function |
||
The function applies the same operation for all the elements of the table of variables with specified variable level.
The module of diagnostics output has special requirements. The special requirements are demanded to the module of diagnostics. In the first, the detailed context of detected error should be reported. In the second, it is necessary to prevent output of many errors of the same type and in the same execution context that is possible when examining a program with the large loops.
At last, it is necessary to allow the user to output diagnostics both on a screen, and in a file for the consequent analysis.
The diagnostics module consists of two modules. The sub-module of context processing monitors current execution context of the program and allows to get a detailed current context description for diagnostics. The sub-module of diagnostics output prints detected errors and filters errors of the same type.
4.4.1 Processing diagnostics context
The program execution context represents description of all current executed loops and current values of all their iteration variables. The current context varies each time, when entering or leaving the parallel or sequential loop or when new iteration execution begins.
The following structure is used to describe program execution context:
| typedef struct _tag_CONTEXT |
| { | ||||
| byte | Rank; | |||
| byte | Type; | |||
| int | No; | |||
| byte | ItersInit; | |||
| long | Iters[MAXARRAYDIM]; | |||
| s_REGULARSET | Limits[MAXARRAYDIM]; | |||
| } | CONTEXT; | |||
| Rank | – | loop rank. | ||
| Type | – | type of chain structure: task region, parallel or sequential loop. | ||
| No | – | unique structure number. | ||
| ItersInit | – | defines, whether at least one iteration of a loop or at least on task of task region was executed. The given flag is important for parallel structures, where between the beginning of a structure and first iteration the additional definitions can be. | ||
| Iters | – | array of current values of loop iteration variables. | ||
| Limits | – | array of initial, last and step values of iteration variables. | ||
Each CONTEXT structure describes one loop of the program. The sequence of such structures completely describes a current program execution context and order of a loop enclosure.
The global table gContext is used for storage the sequence of CONTEXT structures in the system. The root context with number zero is put to the gContext when system is initialized. This context corresponds to main() program procedure.
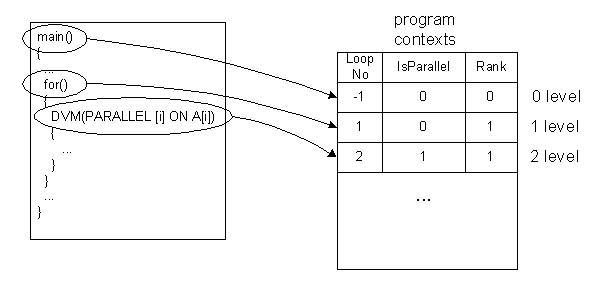
Figure 3. Program execution contexts representation
The following functions are intended to work execution context:
| void cntx_Init(void) |
The function initializes global variables that are used to work with execution contexts. This function also initializes the root context with zero number corresponding to the main program branch.
| void cntx_Done(void) |
The function uninitializes global variables used for the work with execution contexts.
| void cntx_LevelInit(int
No, byte Rank, byte Type, long* pInit, long* pLast, long* pStep) |
| No | – | unique structure number; |
| Rank | – | loop rank; |
| Type | – | structure type: task region, parallel or sequential loop; |
| pInit | – | array of initial values of iteration variables; |
| pLast | – | array of final values of iteration variables; |
| pStep | – | array of steps of iteration variables. |
The function defines a new program execution context. The function is called when the program begins execution of a new parallel or sequential loop or task region.
| void cntx_LevelDone(void) |
The function defines completion of the current program execution context. The function is called when leaving a parallel or sequential loop or task region.
| void cntx_SetIters( AddrType *index , long IndexTypes[] ) |
| index | – | array of current iteration variable values. The rank of the array is equal to current structure rank. | |
| IndexTypes | – | array of index variable types. | |
The function updates values of iteration variables. The function is called when a new iteration or parallel task begins.
| CONTEXT *cntx_CurrentLevel(void) |
The function returns pointer to current context definition.
| CONTEXT *cntx_GetLevel( long No ) | ||
| No | – | context number. |
The function returns pointer to context definition with the specified context number.
| long cntx_LevelCount(void) |
The function returns count of registered program execution contexts.
| long cntx_GetParallelDepth(void) |
An enclosure depth of program parallel constructions (parallel loops and task regions) is returned.
| int cntx_IsInitParLoop(void) |
The function returns current parallel structure execution state.
| long cntx_GetAbsoluteParIter(void) |
The function returns absolute index of current executed loop iteration. For task regions the function returns number of current executed task.
| int cntx_IsParallelLevel(void) |
The function returns not zero value if it is called in the context of parallel loop or parallel task.
| CONTEXT* cntx_GetParallelLevel(void) |
The function returns most nested executed parallel context. It returns NULL if there is no currently executed parallel context.
| char *cntx_FormatLevelString( char* Str ) | ||
| Str | – | pointer to string buffer. |
The function forms description of current loop execution context and puts it into the Str string. The function returns pointer to the end of formed string.
4.4.2 Diagnostics output functions
Dynamic debugger outputs error diagnostic when it is detected. The messages are printed to a screen or file dependently on parameters of dynamic debugger and modes of DVM system. The repeated error in the same context is printed only once. After completion of a program the dynamic debugger outputs summary information about all found errors with a count of error repetition.
The common structure of error message is following:
(<process number>)<context> File: <file>, Line: <line>
(<count> times)<error message>
where:
| <process number> | – | process number where the error occurs. It is issued only if the program is started on several processors. | ||
| <context> | – | context of the
error. It can have one of the following forms: Sequential branch – the error occurs in sequential branch of program; Loop( No(N1), Iter(I1,I2,…) ), …, Loop( No(Nm), Iter(I1,I2,…) ) – the error occurs in structure of m-nested level. |
||
| <file> | – | file name where the error occurs. | ||
| <line> | – | <line> – line number where the error occurs. | ||
| <count> | – | <count> – count of error repetition in the same context. It is printed in the summary information. | ||
| <error message> | – | description of the error. | ||
The following structure is intended to store an error description:
| typedef struct _tag_ERROR_RECORD |
| { | ||||||
| int | StructNo; | |||||
| long | CntxNo; | |||||
| char | Context[MAX_ERR_CONTEXT]; | |||||
| char | Message[MAX_ERR_MESSAGE]; | |||||
| char | File[MAX_ERR_FILENAME]; | |||||
| unsigned long | Line; | |||||
| int | Count; | |||||
| } | ERROR_RECORD; | |||||
| StructNo | – | current structure number. It is equal –1 if there is no current executed program structure. | ||||
| CntxNo | – | current program execution context number. It is calculated as the following: cntx_LevelCount() – 1. | ||||
| Context | – | context description string. | ||||
| Message | – | error message string. | ||||
| File | – | file name. | ||||
| Line | – | line number. | ||||
| Count | – | count of errors of the same type occurred in the same program execution context. | ||||
The following structure is intended to store detected errors:
| typedef struct _tag_ERRORTABLE |
| { | ||||||
| TABLE | tErrors; | |||||
| int | MaxErrors; | |||||
| int | ErrCount; | |||||
| } | ERRORTABLE; | |||||
| terrors | – | the table that contains ERROR_RECORD type elements; | ||||
| MaxErrors | – | maximum number of processed errors; | ||||
| ErrCount | – | current number of detected errors. | ||||
The following functions are intended for work with diagnostics output:
| void error_Init(ERRORTABLE* errTable, int MaxErrors) |
| errTable | – | pointer to initialized table of diagnostics; |
| MaxErrors | – | maximum number of processed errors. |
The function initializes the table of diagnostics.
| void error_Done(ERRORTABLE* errTable) |
| errTable | – | pointer to table of diagnostics. |
The function uninitializes the table of diagnostics and frees memory allocated for table of diagnostics.
| ERROR_RECORD
*error_Put(ERRORTABLE* errTable, char* File, unsigned long Line, char* Context, char* Message, int StructNo, long CntxNo) |
| errTable | – | pointer to table of diagnostics; | ||
| File | – | file name; | ||
| Line | – | line number; | ||
| Context | – | context description string; | ||
| Message | – | error message; | ||
| StructNo | – | structure number; | ||
| CntxNo | – | program execution context number. | ||
The function puts a new error message into the table of diagnostics. The function returns pointer to error diagnostic record in the table.
| ERROR_RECORD
*error_Find(ERRORTABLE* errTable, char* File, unsigned long Line, char* Message, int StructNo, long CntxNo) |
||
| errTable | – | pointer to table of diagnostics; |
| File | – | file name; |
| Line | – | line number; |
| Message | – | error message; |
| StructNo | – | structure number; |
| CntxNo | – | program execution context number. |
The function searches the error message with the specified parameters in the table of diagnostics. The function returns pointer to found error diagnostic record or NULL if error message was not found.
| byte error_Message(char*
To, ERRORTABLE* errTable, char* File, unsigned long Line, char* Context, char* Message) |
||
| To | – | the file name, for diagnostics output. If this parameter is equal to NULL then the STDERR stream is used; |
| errTable | – | pointer to table of diagnostics; |
| File | – | file name; |
| Line | – | line number; |
| Context | – | context description string; |
| Message | – | error message. |
The function registers a new error message in the table of diagnostics. If the table does not have a message with the specified parameters then the message will be put into the table and written into the specified file. Otherwise, the Count field of the corresponded record will be incremented only.
| byte error_Print(char* To, ERROR_RECORD* pErr) | ||
| To | – | the file name, where the diagnostic message will be put. If this parameter is equal to NULL then the STDERR stream will be used; |
| pErr | – | pointer to the error diagnostic record. |
The function writes the specified error message into the file.
| void error_PrintAll( char *To, ERRORTABLE *errTable ) |
| To | – | the file name, where the diagnostic message will be put. If this parameter is equal to NULL then the STDERR stream will be used. |
| errTable | – | pointer to table of diagnostics. |
The function writes all error messages from the table of diagnostics into the specified file.
| void error_DynControl( int code, ... ) | ||
| code | – | error code. |
The function registers a new detected error of dynamic control module.
| void error_DynControlPrintAll(void) |
The function outputs all error messages of dynamic control module.
| void error_CmpTrace( char *File, unsigned long Line, int code ) | ||||
| File | – | trace file name; | ||
| Line | – | line number of trace; | ||
| code | – | error code. | ||
The function registers a new detected error about trace or loop description file structure.
| void error_CmpTraceExt(
long RecordNo, char *File, unsigned long Line, int code, ... ) |
||||
| RecordNo | – | trace record number in the trace file; | ||
| File | – | trace file name; | ||
| Line | – | line number of trace; | ||
| code | – | error code. | ||
The function registers a new detected error of comparing execution results module.
| void error_CmpTracePrintAll(void) |
The function outputs all error messages of comparing execution results module.
| DVM debugger - contents | Part 1 (1 - 4) | Part 2 (5 - 6.4) | Part 3 (6.5) | Part 4 (7) |